KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
What is Kubernetes Right-Sizing and should I care ?

Ray Edwards
VP - NorthEast Sales, Avesha

Kubernetes prime time
The battle for container orchestration began in the early 2010s with the rise of containerization technology. Containerization allows developers to package their applications into small, portable, and self-contained units that can run on any infrastructure, from a laptop to a data center. However, managing these containers at scale can be challenging, which led to the development of container orchestration tools. The battle for dominance in container orchestration has been primarily between Kubernetes, Docker Swarm, and Mesos. Kubernetes, which was originally developed by Google, has emerged as the clear winner due to its robust feature set, large community, and strong ecosystem. Today, Kubernetes is the de facto standard for container orchestration, used by companies of all sizes and industries.
As enterprises seek to modernize their application platforms, they in turn are adopting the use of containers, and following the Kubernetes framework.
It is important to note that Kubernernetes development is not limited to cloud computing only. Today Kubernetes can also run in traditional on-premises data centers, hosted and managed service providers’ infrastructure and even at the edge.
Business leaders can choose to run their applications based on productivity advantages and economics rather and not be restricted based on legacy setups or availability.
Indeed, as the chart below demonstrates, while the actual mix of workloads on the different platforms may shift, customers are not abandoning any of the platforms any time soon.
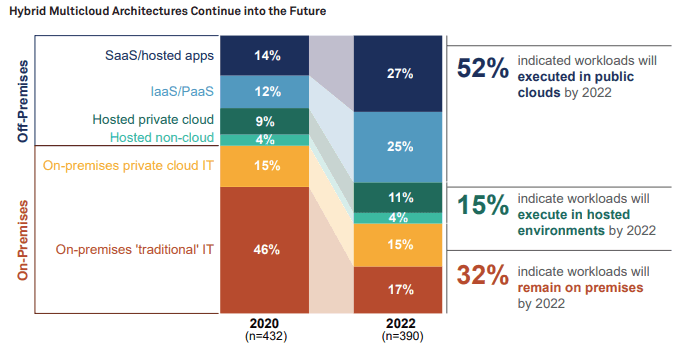
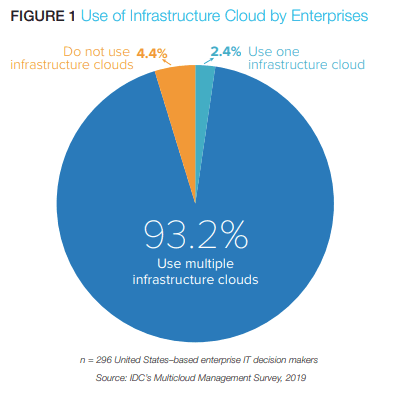
The situation is further complicated by the adoption of multi-cloud deployments.
According to IDC’s Multicloud Management Survey 2019 , a full 93.2% of respondents reported the use of multiple infrastructure clouds within their organization.
Increase of Kubernetes Costs
As the adoption of Kubernetes continues to increase, some organizations are finding that their Kubernetes costs are getting out of control. While Kubernetes is free and open source, there are significant costs associated with running it in production. These costs include infrastructure costs for running Kubernetes clusters, licensing costs for enterprise-grade features, and operational costs for managing and maintaining Kubernetes clusters.
A FINOPs/CNCF survey conducted in May 2021 - ‘Finops for Kubernetes’ provides some very insightful details on the growth of Kubernetes costs overall.
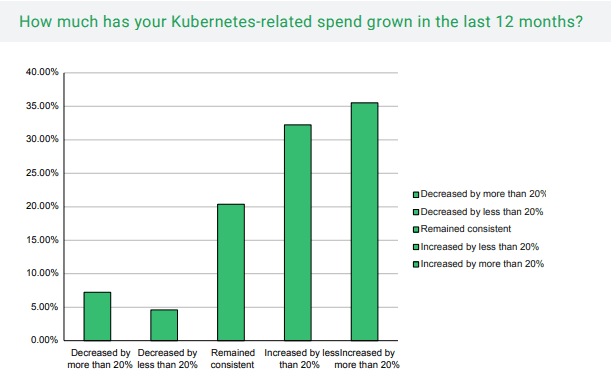
Just 12% of survey respondents saw their Kubernetes costs decrease over the last 12 months.
The bulk share of these costs (over 80%) are related to compute resources. The situation is further exacerbated by the fact that most Kubernetes nodes have low utilization rates across a cluster.
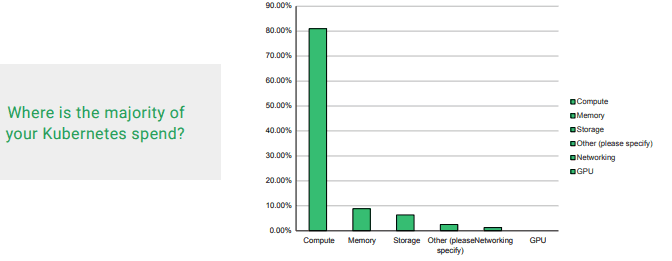
An insightful conclusion from the FinOps 2021 survey should be a wake up call for IT managers.
“The vast majority of respondents fell into one of two camps. Either they do not monitor Kubernetes spending at all (24%), or they rely on monthly estimates (44%). A relative minority reported more advanced, accurate, and predictive Kubernetes cost monitoring processes”
Managing Kubernetes Costs
Until recently, managing Kubernetes costs have been unwieldy.
Kubernetes cost optimization refers to the process of reducing the expenses associated with running Kubernetes clusters. This can involve minimizing resource usage, scaling resources efficiently, and choosing cost-effective solutions for storage, networking, and other components of the Kubernetes infrastructure. Kubernetes can be a powerful tool for scaling and managing your infrastructure, but it can also be expensive if not optimized properly. There are several approaches you can take to optimize your Kubernetes costs. One is to ensure that your workloads are running efficiently, with the right amount of resources allocated to each pod or container. Getting all these settings just right, and adjusting them as workloads change is next to impossible at scale without some sort of automation.
Another is to use auto-scaling features to scale resources up and down automatically based on demand. If your workload or pod usage exceeds the threshold set for a given metric, the auto scaler will increase the pod resource limits or add more pods. Likewise, if resource utilization is too low, it will scale the pods down.
Types of Autoscalers
- Cluster Autoscaler
Autoscaler is a core component of the Kubernetes control plane that makes scheduling and scaling decisions. It detects when a pod is pending (waiting for a resource) and adjusts the number of nodes. It also identifies when nodes become redundant and reduces resource consumption.
- Horizontal Pod Autoscaling (HPA) https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
The Horizontal Pod Autoscaler is a great tool for scaling stateless applications but can also be used to support scaling of StatefulSets, a Kubernetes object that manages a stateful application together with its persistent data.
The HPA controller monitors the pods in the workload to determine if the number of pod replicas needs to change. HPA determines this by averaging the values of a performance metric, such as CPU utilization, for each pod. It estimates whether removing or adding pods would bring the metric’s value closer to the desired value specified in its configuration.
- Vertical Pod Autoscalers (VPA)
VPA is a mechanism that increases or decreases CPU and memory resource requirements of a pod to match available cluster resources to actual usage. VPA only replaces pods managed by a replication controller. So it requires use of the Kubernetes metrics-server.
A VPA deployment consists of three components: Recommender—monitor resource utilization and estimates desired values Updater—checks if the pod needs a resource limit update. Admission Controller—overrides resource requests when pods are created, using admission webhooks.
- Kubernetes Event-Driven Autoscaler (KEDA)
KEDA is a Kubernetes-based Event Driven Autoscaler developed by Microsoft and Red Hat.. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed.
KEDA is a single-purpose and lightweight component that can be added into any Kubernetes cluster. KEDA works alongside standard Kubernetes components like the Horizontal Pod Autoscaler and can extend functionality without overwriting or duplication. With KEDA you can explicitly map the apps you want to use event-driven scale, with other apps continuing to function. This makes KEDA a flexible and safe option to run alongside any number of any other Kubernetes applications or frameworks.
To automatically scale a workload using predefined metrics, you might use a pod or workload auto scaler (e.g., HPA, VPA, KEDA). Pod scaling impacts the resource provisioning within a node or cluster, but this scaling approach only determines how existing resources are divided between all workloads and pods. By contrast, node scaling gives pods more resources overall, by scaling up the entire cluster.
With the intense focus on cost reduction these days, it is only natural that IT leaders will consider autoscaling as a way to mitigate over-provisioning, and employ a just-in-time scaling approach, based on workload needs.
The question is - which approach is best.
- Manual autoscaling - Any practitioner of cloud computing will admit that trying to manage resources ‘manually’ is a recipe for disaster. Unless you have a completely static environment or a very small Kubernetes deployment, it will be impossible to keep up with workload needs by scaling your pods manually.
- Automation - The vast majority of open source and commercial autoscaling tools introduce some type of automation into the process of managing Kubernetes resources. Administrators will set some minimum /maximum thresholds and the tool will automatically scale clusters or pods up/down based on resource needs and availability. This in itself is a great step forward in managing kubernetes costs.
- Intelligent Autoscaling - The next paradigm in Kubernetes autoscaling is one that incorporates Intelligence and Reinforcement Learning into the automation process. Avesha’s Smart Scaler product introduces Machine Learning AI for autoscaling and was recently named as 100 edge computing companies to watch in 2023.
Instead of using generic autoscaling templates, Avesha’s patented Reinforcement Learning process actually learns the specific workload characteristics and adjusts the autoscaling process to match. It works natively with HPA and KEDA tools.
This Proactive Scaling therefore allows IT shops to finally offer Kubernetes SLOs - something that was unheard of until now.
When coupled with KubeSlice (the other product in the Avesha Platform) , SmartScaler extends the autoscaling into a multi-cloud, multi-region, multi-tenant setup - providing true autoscaling across all kubernetes infrastructure – enabling the IT manager to focus on workload optimization, rather than infrastructure integration.
(KubeSlice creates a flat, secure virtual network overlay for Kubernetes that eliminates the north-south traffic between Kubernetes deployments.)
Not only does reducing Kubernetes operating costs make good business sense, but it can also contribute to a more sustainable future by minimizing carbon footprint , creating a win-win situation for both businesses and the environment.




















Copied