KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
Microservice Twins in Kubernetes - breaking new grounds

Ray Edwards
VP - Northeast Sales, Avesha

Microservice Twins in Kubernetes - breaking new grounds
Originally applied in the world of manufacturing, the term ‘Digital Twin’ is increasingly becoming a top strategic concern in the world of devops these days.
For those interested in its history, these are two great links that provide a great background.
Mysterious history of Digital Twins
David Essex has another Digital Twin article on Tech Target that I think is a great read
The most famousapplication of Digital Twin technology was at NASA in 1970 where engineers needed to troubleshoot problems aboard Apollo 13 when it malfunctioned on its way back to earth. Creating a full scale model was impossible given the time restrictions, so the engineers opted instead to spin up Digital Twins of the main control system and electrical systems in under 2 hours. This rapid response helped them use the Digital Twins to identify problems, find appropriate solutions and save the lives of the 3 astronauts on board.
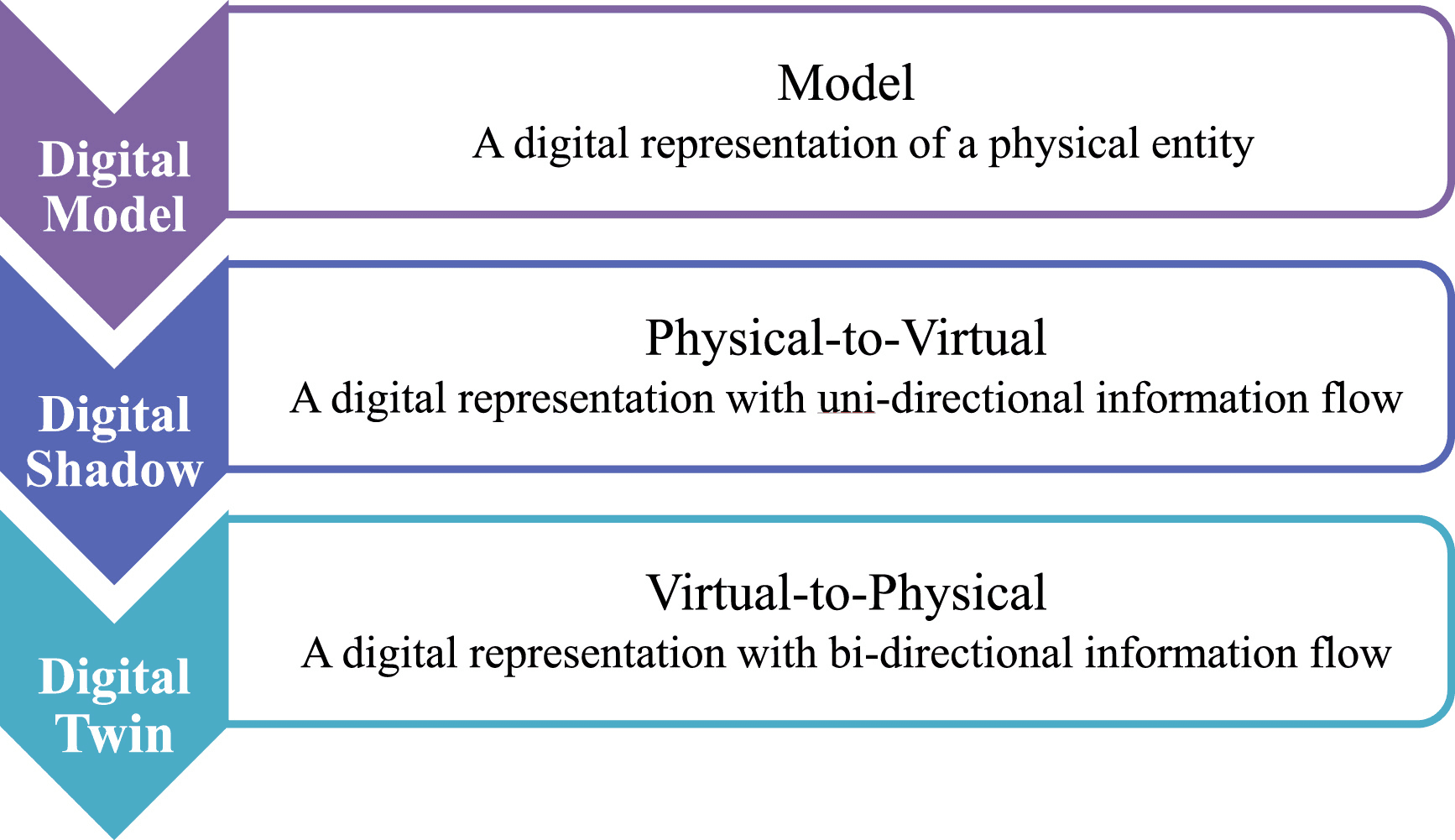
For a formal definition, we look to the Encyclopedia of Production Engineering definition : “The Digital Twin is a representation of an active unique “product” which can be a real device, object, machine, service, intangible asset, or a system consisting of a product and its related services”
From an IT leader's perspective, a Digital Twin is the creation of a simulated environment that mimics an actual running environment (physical or software/hardware). It is important to understand the distinction between a pre-production environment (a standalone environment where software is thoroughly tested before it is put into production), and a DTE which simulates both the software and the infrastructure, and has a bi-directional data flow with the original, which therefore allows us to simulate the whole environment for any changes in real time.
Their application in different industries may vary, but all Digital Twin Environments (DTE) have a few core common components.
- The actual environment
- The simulated environment
- A method to synchronize the simulated environment to reflect changes in the actual environment.
The distinction between modeling and Digital Twin is also important to keep in mind.
https://www.sciencedirect.com/science/article/pii/S277266222300005X
Two key requirements for a DTE are that the changes in the production environment are reflected in the DTE as quickly as possible (frequency) and as accurately as possible (fidelity).
DTEs have long been used to monitor and measure manufacturing equipment but savvy leaders have adapted the Digital Twin concept to software development and cloud transformation projects.
Among the more common use cases are:
- DTEs would make it possible to test out the impact on our entire infrastructure as we migrate applications to the cloud.
- Developers can evaluate individual microservice iteration on their efficiency of CPU/memory usage prior to release
- DTEs can make it possible to surface unforeseen dependencies when changes are made to an application
- The impact on latency and network performance at full production scale
- Evaluating specific bursting-to-cloud scenarios to determine the best burst platform based on application criteria
- Determining if migrating an application to the cloud will indeed yield better cost/performance numbers prior to actually doing so.
Any of these use cases would be almost impossible to evaluate without using some sort of DTE simulation. Manually creating a staging environment, and then attempting to tweak individual software and hardware settings to match the production environment is an almost impossible task, given the vast number of data points, metrics and settings that would have to be adjusted.
The role of Kuberntes in Digital Twin projects
Applying the DTE framework to Kubernetes environments opens up new realms of application performance management and optimization.
Kubernetes architecture model and its declarative deployment options enable teams to set up consistent application environments across multiple platforms quickly with ease. Regardless of the underlying infrastructure, a Kubernetes container platform, when set up properly, allows us to completely virtualize the infrastructure it is running on.
Another benefit of Kubernetes is its agility in software rollout. With a centralized control plane and robust container orchestrator, software upgrades and rollouts can be achieved quickly and consistently.
A third benefit of a Kubernetes environment is the many logs and metrics that are produced by its containers, pods and services - enabling the monitoring and troubleshooting of its components in great detail.
Taken together, Kubernetes enables IT shops to rapidly create an environment and test out software changes prior to deploying them into production.
Microservice Twin
A key concept of the Kubernetes framework is the architectural approach of breaking down an application into a set of loosely coupled services, or micro-services. Each microservice performs a specific function and runs as a separate process. Each process and function within an overall application can be decomposed into individual microservices, which in turn allows developers to improve and optimize the operations separately.
In a Kubernetes world, Avesha’s Kubeslice enables the creation of a twin of a specific microservice. By treating a microservice as a first class citizen, application owners can finally analyze specific microservices as they are developed and deployed. This innovative idea of a “Microservice Twin Pattern” is very nicely expounded by Bilgin Ibryam in his recent article on InfoQ.
What is insightful in the Microservice Twin Pattern is the concept of creating remote twins , usually on a cloud platform, that allows the service to be enhanced, connect to different sources / targets all without impacting the original microservice itself. Various security policies, API connections, credentials, networking and even data sources can be incorporated into the ‘twin’ service while keeping the source microservice unchanged. Not only does this enable the testing of the microservice on different platforms, it also provides additional functionality that can be enhanced on the cloud.
The fundamental requirement for a Microservice Twin is a low latency, isolated, secure connectivity between the microservice and its twin in the cloud. This is enabled by Avesha Kubeslice. Interested readers can read all about Kubeslice on my blogs but it is important to note that the connectivity should not be via a service mesh or API gateway, but rather a Layer 3 direct connection to ensure low latency and data fidelity.
With new innovative tools on the market, such as Avesha AI based SmartScaler and Kubeslice, DevSecOps and FinOps teams can address several new challenges in the digital transformation landscape.
Don’t Stop there !
Below I outline 2 additional use cases of Microservice Twins.
Cloud Migration
With all the costs and resources that companies allocate to Cloud Migration projects, having an AI Microservice Twin setup is imperative during the planning and operational phases. By enabling a granular Microservice Twin, Kubeslice allows operations team to not only create a replica of an on-prem microservice in the cloud, it also allows the team to make changes to the cloud microservice setup and obtain real time view of impact created by tweaking the infrastructure (such as using larger storage classes). Horizontal and vertical scaling scenarios, external trigger events and application availability SLOs can all be evaluated on the cloud environment before any application is actually migrated. Application owners can get a true view of costs and performance and make informed decisions about migrating the application.
Environment Modeling for Multi-Cloud Machine Learning Operations (MLOps)
Artificial Intelligence and machine learning is all the rage today and almost every enterprise has or will soon embark on AI projects. What differentiates machine learning from human learning is the ability to process vast amounts of data in a short amount of time.
In fact, the effectiveness of machine ‘learning’ is improved the more data we process. Where the challenge arises is the movement of this data between platforms.
To illustrate this point, consider a typical pharmaceutical company that has global manufacturing facilities (edge IOT) and multiple associated microservices (some running on-prem, and others running on separate cloud platforms).
Any process improvement AI/ML projects would require that all the microservices and data are correlated and connected somehow. The default approach would be to consolidate all the data into a central repository and then apply data science to this massive data. The obvious problem with this approach is the movement of large data sets that is required, in addition to the delay before data is available for ML.
Even then, this approach does not overcome the need for cloud localization. All cloud vendors are not equal. An application running on AWS will not easily be replicated on Azure or vice versa. The difference is made more acute if the application uses any of the native cloud services offered by the vendor.
The enterprise may decide on a round-robin strategy - refining a model with the data on one cloud platform, then applying that model and data to a second platform followed by a third , in a round robin fashion. The inherent problem with this approach of course, is the high egress cost for data movement from one cloud platform to another.
The ideal solution of course is to create a Microservice Twin on each platform. The learning model can be applied to one platform (and its corresponding data), and the resulting algorithm then applied to the second cloud platform applications and all data residing on that platform - with no movement of data between the cloud instances. Again, a secure, low-latency layer 3 connectivity using Kubeslice is required to effectuate this approach.
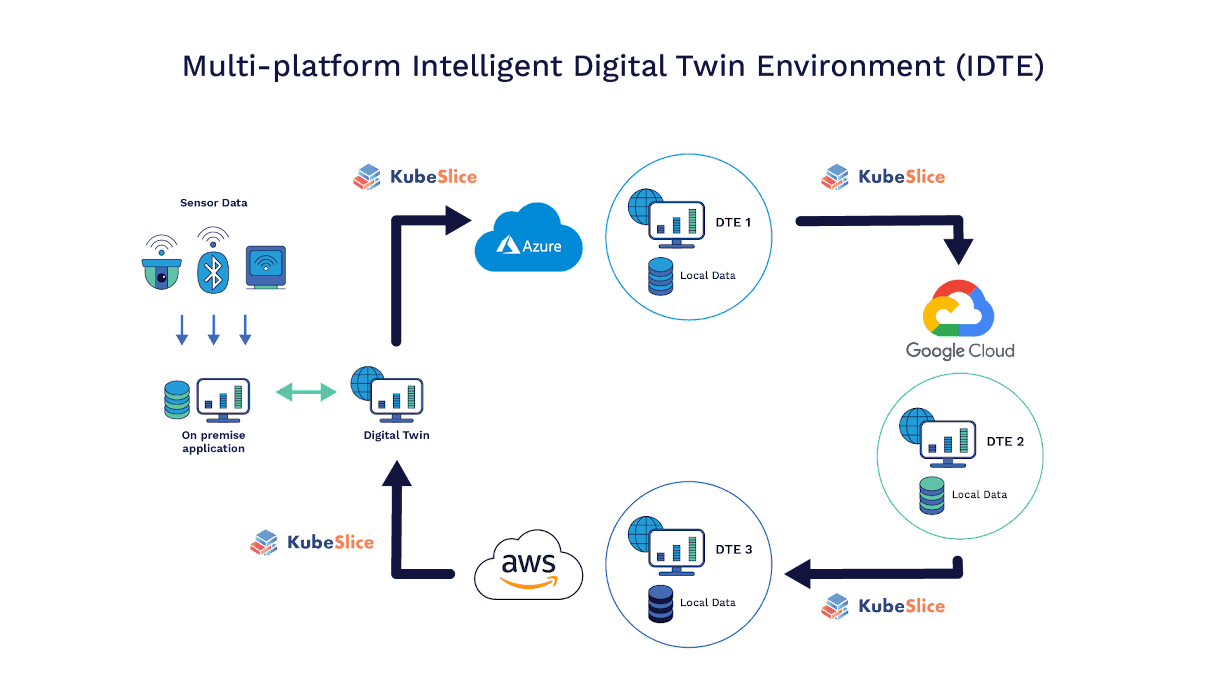
New sensor data or new models can be quickly adopted, regardless of where it comes from or where the application is running - ensuring rapid analysis and near real-time decision making.
These are just three examples of Intelligent Digital Twin Environments helping companies unlock their cloud potential in software development and operations.
Summary
What was once a framework only used in manufacturing, the Digital Twin concept is increasingly being adopted in the DevOps world. Here, I have outlined how, combining the architecture of Kubernetes, with the multi-platform connectivity of Kubeslice, enterprises of any size can implement Microservice Twins for their own process improvement - on premise or on any cloud platform .




















Copied