KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
7 Common mistakes in a Multi-Cloud Journey

Ray Edwards
VP - NorthEast Sales, Avesha

Your executive leadership launched a ‘Cloud First’ strategy with much fanfare a few months ago. At first it was simple and seemed inexpensive to move workloads to your primary cloud service provider. But now, you feel the cloud provider is taking you for granted - you’ve lost all price negotiation power, and SLAs and response levels are not what it used to be. To make matters worse, your new cloud service bill seems to be out of control.
You are confronted with what is known as the “Cloud Paradox” - the very benefits that made the move to the cloud as a compelling strategy are now causing costs to spiral, stifling innovation and making it near impossible to repatriate workload from the cloud.
Most large enterprises have started cloud adoption and now find themselves in the trough of cloud paradox where their cloud bills are starting to bite. They are facing margin pressures of their cloud infrastructure. Trying to optimize cloud costs in turn is reducing their ability to innovate freely.
The folks at Azul Systems have published a very interesting Cloud Adoption Journey chart that highlights the technology maturity curve as customers adopt cloud platforms. Similar in concept to the Gartner Hype cycle, technology leaders have to be mindful of the various challenges and pitfalls of cloud adoption before they can truly realize the value optimization of cloud computing.
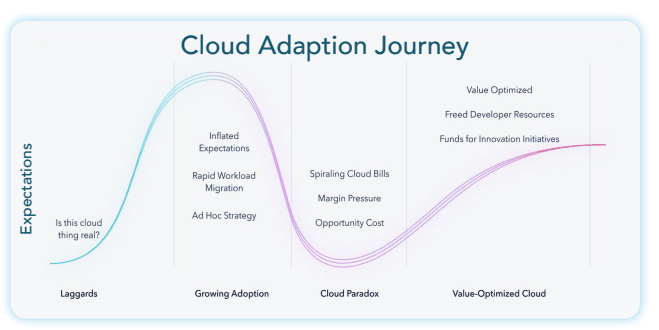
For those that find themselves in the trough of the journey, and are thinking of ways to maintain control of your cloud strategy; and break out of the cloud paradox, you are not alone.
Here, I will share several initiatives that can help IT leaders avoid getting stuck in the Cloud Paradox, and move further along the curve. Only then can enterprises realize the true benefits of cloud adoption all while optimizing their cloud spend.
Before we delve into that however, it is useful to understand why a Multi-Cloud deployment may be a worthwhile strategy in the first place.
Guard against Vendor Lock In
The number one reason business leaders consider a Multi-vendor multi-cloud adoption is to avoid putting all their ‘eggs’ into one basket. Amazon, Azure, GCP and others continue to enhance their cloud services and any enterprise that wants to stay at the forefront of technology improvements needs the flexibility to utilize the platform that best suits their needs. Not to mention the obvious loss of negotiation power when one is beholden to any single cloud provider.
Compliance and Data sovereignty
Companies doing business globally may be subject to rules and regulations that require customer data to be located in a particular region or country. The flexibility to choose a vendor that enables such data localization is another essential reason for a multi-cloud approach.
Workload specialization and costs
As mentioned earlier, cloud providers continue to offer specializations for workloads and features that may address the specific needs of a particular application. For example, AWS may offer some advances in ML application but your IOT application may be most suited to a GCP set of enhancements. Having a multi-cloud approach ensures you are able to optimize an application based on need and costs as appropriate.
Forestall Data Gravity challenges
The idea of data gravity was first coined by Dave McCrory in 2010. His view was that once data is stored anywhere, it starts to “grow” in size and quantity. That mass attracts services and applications, because the closer they are to the data, the lower the latency and better the throughput. The resulting challenge is that as the data gravity increases, it becomes almost impossible to migrate that data to a different platform. What results is ‘artificial data gravity’ where data is centralized not because of any benefits or requirements, but rather because it is too difficult to do otherwise.
By deploying a “multi-cloud first” approach, customers can retain data where it is created (e.g at the edge) and optimize the applications to utilize real-time processing and secure multi-cluster networking instead.
Optimize Geographical Performance
Since the performance and latencies differ between cloud providers in different regions, a multi-cloud application can utilize the provider with the best characteristics for a given region or geography.
Application Resiliency
While cloud outages are rare, they are extremely disruptive when they do occur. The recent Fortune technology Article on Cloud Outages estimates a downtime cost of $365K per hour for cloud outages on business.
A multi-cloud approach is an effective defense against such risks.
Now that we’ve outlined some of the reasons WHY you should incorporate a multi-cloud approach to your devops projects, let’s discuss some of the common mistakes to avoid when establishing a multi-cloud strategy.
Mistake #1 - Relying on custom resources
Ideally, your application should not be reliant on custom resources from your cloud vendor. Resources that you use (networking, compute, memory, storage) should be virtualized using industry standard interfaces - CNI, CSI etc. This enables you to move an application between platforms without having to unwind custom hooks. Adopt a true Infrastructure as Code (IaC) methodology.
Mistake #2 - Overlooking inter-cloud network connectivity
One of the often overlooked aspects of Multi-cloud deployments is the network connectivity between applications running on different cloud platforms. Using a global load balancer to route traffic to individual application ‘islands’ is a suboptimal solution at best. Data and Metrics that have to travel between these isolated clusters have to navigate network boundaries via North-South traffic, and can only do so asynchronously.
Users should instead use tools such as KubeSlice to create a software defined network tunnel between the clusters / Clouds that ensures security and lowers the network latency. Thus, data and metrics can connect synchronously, via an East-West pathway between the clusters. In addition, the connection can be isolated at the individual namespace level - complying with zero trust application deployment model.
Mistake #3 - Simply using Autoscaling to control costs vs. Intelligent Autoscaling and Remediation
Intelligent autoscaling is a type of autoscaling that uses machine learning to predict future resource demand and scale accordingly. This can help to improve the performance and scalability of cloud-based applications, while also reducing costs.
Traditional autoscaling approaches are based on simple rules, such as scaling up when CPU utilization reaches a certain threshold. However, these rules are reactive in nature, and can be too simplistic, leading to over- or under-provisioning of resources. Intelligent autoscaling, on the other hand, uses machine learning to learn the patterns of resource usage and predict future demand. This allows it to scale more effectively and efficiently.
There are a number of different ways to implement intelligent autoscaling. Some popular approaches include:
- Using machine learning models to predict resource demand. This can be done by analyzing historical data, such as CPU utilization, memory usage, and traffic patterns.
- Using reinforcement learning algorithms to learn the optimal scaling policies. This can be done by trial and error, or by using a simulation environment.
- Using a combination of machine learning and reinforcement learning. This can be a more effective approach, as it can combine the strengths of both approaches.
Intelligent autoscaling is a relatively new technology, but it is becoming increasingly popular. As cloud-based applications become more complex, the need for intelligent autoscaling will only grow.
Using Intelligent Autoscaling tools such as Avesha SmartScaler, enterprises can ensure their multi-cloud applications also benefit from:
- Improved performance: Intelligent autoscaling can help to improve the performance of cloud-based applications by ensuring that they have the right amount of resources available. This can help to reduce latency and improve the user experience.
- Reduced costs: Intelligent autoscaling can help to reduce costs by preventing over-provisioning of resources. This can save businesses money on their cloud bills.
- Improved scalability: Intelligent autoscaling can help to improve the scalability of cloud-based applications by allowing them to adapt to changes in demand. This can help businesses to avoid downtime and ensure that their applications are always available.
- Instantaneous action: Unlike some of the common autoscaling tools, SmartScaler not only provides autoscale recommendations, but can actually make those changes in real time, instead of waiting for a manual operation. This not only saves time, but can also ensure specific application SLOs.
Mistake #4 - Cluster monitoring vs. fleet monitoring
When we’re only monitoring a single cluster, it is relatively easy to install Prometheus and Grafana, two open-source tools that are often used together for monitoring and observability.
- Prometheus is a monitoring system that collects metrics from a variety of sources, such as applications, services, and infrastructure. It stores these metrics in a time series database, which can be queried to generate alerts and visualizations.
- Grafana is a visualization tool that can be used to create dashboards and charts from Prometheus data. It provides a wide range of features for visualizing metrics, including graphs, tables, and maps.
The situation becomes infinitely more complex when we want to monitor a fleet of clusters on a single dashboard. Installing a Prometheus server and Grafana dashboard for every cluster quickly becomes unwieldy. On the other hand, exporting metrics from different clusters, from multiple cloud platforms, to a centralized control center tends to create IP address conflicts and challenges in metrics latency
Here again, a tool such as KubeSlice can help create a virtual, synchronous data plane for all Prometheus metrics from each cluster to be transmitted to a central control dashboard via a low latency synchronous connection.
Mistake #5 - Not planning for MultiCloud Resiliency and Backup
A full discussion on Resiliency and backup in Multi-Cloud setup is beyond the scope of this blog, but I’ve covered this in a previous blog post which can be found here. There is also an in depth webinar by the WeMakeDevs folks on Zero RTO DR for Kubernetes for those that are interested.
Mistake #6 - Shortchanging Multi-Cloud security
Cloud Security causes trepidation in most application owners’ minds, multi-cloud security even more so. With a few best practices however, these risks can be ameliorated. Since each cloud platform may have its own security features and requirements, adopting a cloud-agnostic security stance frees you up from dependency on any one tool or security model.
Some of the key best practices to ensure multi-cloud security include:
- Implementing consistent security policies across all cloud platforms. This will help to ensure that all of your data and applications are protected to the same level.
- Using a centralized cloud security management platform. This can help you to simplify the management of your security policies and configurations across multiple cloud platforms.
- Monitoring your cloud environments for security threats. This will help you to identify and respond to threats quickly.
- Encrypt your data (obviously!)
- Store encryption keys separately (in a central repository) from cloud workloads
- Rotate the keys regularly
- Use IAM Federation for SSO
- Educating your employees about cloud security best practices. This will help to reduce the risk of human error.
Mistake #7 - Not having an escape plan
It is surprising to see so many business leaders embark on a public cloud journey with no exit plan. Even if today’s financial analysis makes it a no-brainer to move applications to a cloud vendor - those rosy numbers may change over time, or performance / service may degrade. It is important to have a backup plan on how to repatriate applications and services.
To quote the famous line by Robert De Niro in the movie Ronin ; ”I never walk into a place I don't know how to walk out of.”

David Heinemeier Hansson has a great blog on Cloud Repatriation and what was the analysis that led him down that path.
Another extreme case of cloud repatriation is that of Dropbox who saved over $75 million over 2 years by moving much of their workload from public cloud to colo facilities with custom infrastructure. Sarah Wang and Martin Casado of Andreessen Horowitz used the Dropbox example in their groundbreaking article The Cost of Cloud, a Trillion Dollar Paradox , a worthy read.
Whether we like it or not, the public cloud has become an integral part of our technological landscape and is poised for further growth. Forward-thinking leaders should acknowledge this reality and instead of relying solely on a single cloud provider, they should adopt a multi-cloud strategy to mitigate potential future uncertainties.
Some of the key benefits of a multi-cloud strategy include:
- Increased flexibility and scalability: By using multiple cloud providers, organizations can choose the best services for their specific needs. This can help to improve flexibility and scalability, as well as reduce costs.
- Improved resilience: By spreading their workloads across multiple cloud providers, organizations can improve their resilience to outages and other disruptions.
- Increased security: By using multiple cloud providers, organizations can reduce their reliance on any single provider. This can help to improve security by reducing the risk of a single point of failure.
With the right approach, multi-cloud can be a safe, secure, and economical path. However, it is important to have a clear understanding of the risks and challenges involved. Tools such as Kubeslice can help to mitigate these risks and make multi-cloud a more manageable reality.




















Copied