KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
Kubernetes resiliency (RTO/RPO) in Multi-Cluster deployments

Ray Edwards
VP - NorthEast Sales, Avesha

Ah Kubernetes! The panacea to all our DevOps challenges.
Kubernetes is the open source container orchestration tool that was supposed to speed up software delivery, secure our applications, lower our costs and reduce our headaches, right?
Seriously though, Kubernetes has revolutionized how we write and deliver software. And with the proliferation of EKS, AKS, GKE, Red Hat OpenShift, Rancher and K3s, Kubernetes has truly won the container orchestration battle. As we expand our applications, cloud platforms, and data, we start to identify areas where Kubernetes is not quite fulfilling the requirements for security and ease of use. Therefore, we need to find ways to help Kubernetes in order to keep up with our growth.
Kubernetes practitioners have turned to third-party tools for networking, security, and resiliency for stateful apps. This helps to make their deployments more reliable.
In this blog, we’ll delve a little deeper into data resiliency for Kubernetes apps.
Kubernetes was designed to solve the challenges of application orchestration - the assumption is that Kubernetes nodes are ephemeral. In reality however, applications do consume and/or produce data. This is referred to as StatefulSets in Kubernetes. Additionally, Kubernetes objects, CRDs, artifacts etc are all details that need to be available in cases of cluster failure - hence the realization that even Kubernetes deployments need a DR strategy.
The Rise of StatefulSets
StatefulSets are designed to handle stateful workloads that require unique network identifiers and stable storage. Each instance of Databases, message queues, or distributed file systems, typically requires stable network identity and persistent storage. StatefulSets address this challenge by providing ordered, unique network identifiers and persistent storage for each pod in the set. There are of course a large contingent of Kubernetes storage deployments that rely on static volume attachments of course, but they do not have the horizontal scaling capabilities, and thus are not part of this blog discussion for now.
In addition to providing uniqueIDs and scaling, StatefulSets provide the ability to mount persistent volumes to each pod. This allows stateful applications to store and access data that persists across pod restarts or rescheduling. Each pod in a StatefulSet receives its own unique persistent volume, enabling data locality and minimizing the impact on other pods.
The Container Storage Interface (CSI) standard is the most widely used API standard. It enables containerized workloads in Kubernetes to access any block or file storage system. Released at the end of 2019, the Container Storage Interface driver with snapshot opened the doors to StatefulSets. See Kubernetes CSI
The Cloud Native Computing Foundation (CNCF) framework includes various projects to meet the storage requirements of Kubernetes. However, practitioners must be knowledgeable in storage fundamentals. This is not a skill usually associated with DevOps.
Companies like Portworx by Pure, Rancher Longhorn , Rook and LINBIT are setting a new standard for container storage. (in addition to vendor offerings from NetApp and HPE). They are providing several enterprise features to make container storage more efficient.
With that background, we turn to the considerations for Multi-cluster database resiliency in Kubernetes.
Single Cluster Apps
For applications running in a single cluster, Kubernetes (together with the CSI storage component) provide a feature for volume replication. Each persistent volume can be set to have a number of replica copies (typically 3) locally.
Kubernetes will take action if a node fails. It will restart the service on a new node and attach it to a replicated version of the volume. This helps to prevent data loss. (Setting aside static CSI or NFS drivers for now)
For tools that replicate data locally, the data is copied synchronously, as it is a single local cluster. Restarting the node is done instantly with the Kubernetes control plane. Therefore, the recovery time is considered zero.
From a recovery point of view, this is considered to be ZERO Recovery Time Objective (RTO). The Recovery Point Objective (RPO) may also be ZERO in this case, but this of course would depend on mitigating for data corruption, journaling etc.
Zooming out to complex environments reveals a murkier picture. These environments include clusters that span multiple clusters, platforms, and even cloud providers.
Multi-cluster database resiliency
Understanding the why and how of Multi Cluster Kubernetes can be difficult. Fortunately, this article by our friends at Traefiklabs provides a clear explanation of Kubernetes Multi Clusters in detail.
The architecture of a multi cluster Kubernetes is depicted in the diagram below :
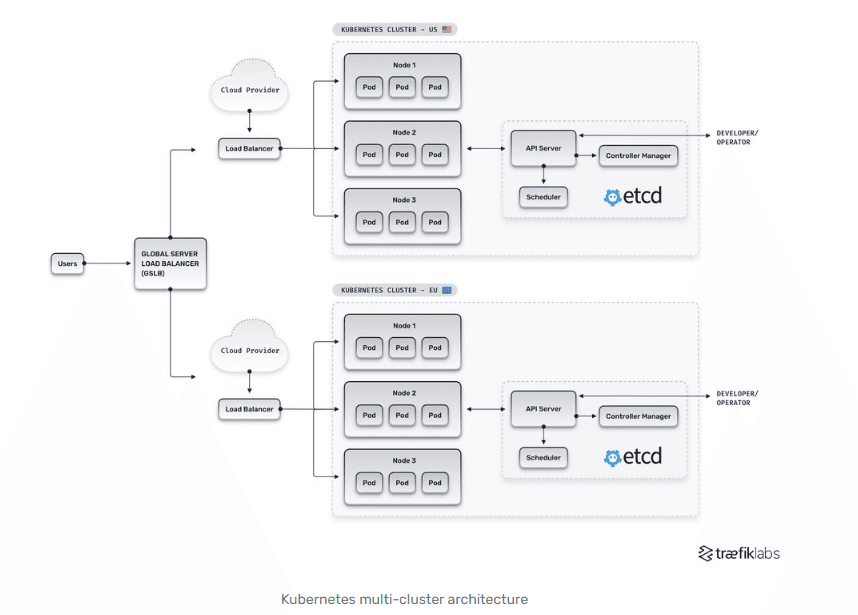
What is pertinent in our discussions is the traffic route between these clusters. From a user perspective, application requests are routed to their US cluster or EU cluster by the global load balancer.
What happens when a pod from Node 1 in US-Cluster needs to communicate to Node 1 on the EU-Cluster? This could present a challenge due to the distance and complexity between the two clusters. At a minimum, data must travel through at least two network boundaries, exiting the US cluster, crossing the Atlantic, and entering the EU cluster.
This network traffic flow between a local network and external networks is referred to as North South traffic. "North" refers to outbound traffic from the local network to external networks. "South" refers to inbound traffic from external networks to the local network.
From a data plane perspective, the North/South traffic between clusters introduces a higher level of latency and reduced reliability when compared to traffic within a local cluster. Whereas traffic within a cluster is synchronous (fast, reliable) ; traffic between remote clusters is thus asynchronous (slower, less reliable).
For those wishing to learn more about synchronous and asynchronous traffic may want to review this article.
How does North/South traffic and synch/asynchronous communications relate back to Kubernetes Multi-cluster database resiliency?
A CSI storage connector in Kubernetes uses synchronous communication for traffic within a local cluster. This means that data is written simultaneously to the primary and replica data volumes.
Data for remote clusters is written locally first. Then, a snapshot copy of the data is shipped to the second cluster on a regular schedule. This is done asynchronously.
This difference in approach also has implications for data resiliency and how data is recovered after a failure.
Kubernetes recovery in a disaster recovery scenario within a local cluster is instantaneous. This is due to data being simultaneously copied to the local replica. As a result, data availability is also instantaneous.
In technical terms, there are two metrics that we track. Recovery Time Objective (RTO) is the time it takes to recover from a failure. Recovery Point Objective (RPO) is the maximum allowable data loss.
Thus, DR within a local Kubernetes cluster can be said to have Zero RPO / Zero RTO
(For an insightful discussion about RPO and RTO considerations in Kubernetes, I highly recommend this post by Bijit Ghosh and another one by Matt LeBlanc.)
In a remote cluster situation however, the picture is somewhat different. When assessing a multi-platform or multi-cloud application, a Cloud Architect or SRE should consider how asynchronous replication impacts the Recovery Time Objective (RTO). Shipping the replica copy, traveling North/South and restoring it on the active cluster at the recovery site all take time. This means that DR operations have a time lag.
This time lag can be significant. Conservative estimates show that CSI solutions can reduce the RTO to 15 minutes. This means we can have a RPO of zero and a RTO of 15.
Most DevOps teams and Cloud Architects focus on single cluster, single region and single platform deployments. They may not consider DR architectures and requirements. As a result, many early adopters may be satisfied with an RTO of 15 minutes.
Traditional infrastructure architects and data owners may want to explore new solutions on the market. These solutions can help them reach a close-to-zero recovery time objective and disaster recovery across multiple Kubernetes platforms.
Tools such as KubeSlice can lower RTO thresholds by establishing a low latency data plane interconnect between multiple clusters or platforms. This helps to enable faster recovery for Kubernetes applications and data.
KubeSlice converts North/South traffic into East-West network traffic via application level virtualization across a secure/encrypted connection, thereby eliminating the need to traverse network boundaries. This creates a lower latency connection for the data plane, and enables synchronous replication of data to the DR site.
KubeSlice makes the remote cluster seem local to the primary cluster. This enables recovery that is close to having Zero Recovery Time Objective (RTO).
Regardless of which recovery scheme is employed, application owners should carefully consider their application and data resiliency needs and plan accordingly.
As the Data on Kubernetes report points out, a full one-third of organizations saw productivity increase twofold by deploying data on Kubernetes, with gains benefiting organizations at all levels of tech maturity. Kubernetes Zero RTO resiliency in MultiCluster deployments
Interested in learning more? Attend this Webinar ZERO RTO Kubernetes DR

Summary
Container Storage Interface (CSI) standard and projects like Portworx and Rancher Longhorn are a great start towards a Software Defined Storage approach for Kubernetes persistent apps.
The article explores Multi-cluster database resiliency in Kubernetes, starting with the resiliency of single-cluster applications. It explains how Kubernetes handles volume replication in case of node failures, ensuring zero recovery point objective (RPO) and zero recovery time objective (RTO) within a single cluster. However, the complexity arises when dealing with multi-cluster environments spanning multiple platforms and cloud providers. The challenges of North/South traffic and asynchronous communication between remote clusters are discussed, and the implications for data resiliency and recovery in disaster scenarios are explained.
The article introduces KubeSlice as a tool that can lower RTO thresholds by establishing a low latency data plane interconnect between multiple clusters or platforms. It converts North/South traffic into East-West network traffic, enabling faster recovery for Kubernetes applications and synchronous replication of data to the disaster recovery (DR) site. The importance of carefully considering application and data resiliency needs is emphasized, and the benefits of deploying data on Kubernetes are mentioned.
Overall, the article focuses on the challenges and solutions related to data resiliency in Kubernetes, particularly in multi-cluster deployments, and highlights the role of tools like KubeSlice in achieving faster recovery times.
Credits: Michael Courcy, Tau M., Brendan Pascale, Michael Levan




















Copied