KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
Bursting Workloads to the Cloud

Ray Edwards
VP - Northeast Sales, Avesha
Best practices for success.
The journey to the cloud is well and truly underway at most large organizations today. Whether your organizational goals are to achieve lower operational costs, to increase agility of DevOps, or even to accelerate time to market - cloud adoption is one of the main ‘top of mind’ agenda items for most CIOs these days.
Add to that the efforts at shifting CapEx costs to OpEx expenses, with a desire for utility-like payments, and it’s easy to understand the popularity of moving workloads to the cloud.
Not all workloads however, can or even should, be migrated entirely to the cloud. There are several key reasons why large enterprises may opt to keep their workloads on-premise:
- Security and Compliance: Some industries have strict regulatory requirements or face data governance restrictions, making it necessary to maintain control over data by keeping it on-premises.
- Data Sensitivity: If an organization deals with highly sensitive or proprietary data that requires stringent protection, they might opt for on-premises solutions to have complete control over data security protocols and encryption methods.
- Cost and Investment: For some companies, especially those with significant existing on-premises infrastructure, it might be more cost-effective to continue using their current resources rather than investing in migrating to the cloud.
- Performance and Latency: Certain applications or workloads, especially those that require real-time processing or have low-latency requirements, might perform better when located on-premises due to direct access to local resources.
- Legacy Systems and Dependencies: Organizations with legacy systems, complex integrations, or specific hardware dependencies might find it challenging to transition
to the cloud. - Control and Customization: On-premises solutions offer more control over hardware, software, and configurations. This level of control allows for customized solutions tailored to specific needs, which might not always be achievable in a cloud environment.
- Internet Dependency Concerns: On-premises solutions eliminate the risk of service disruption due to internet outages or connectivity issues.

Even large IT shops realize however that infrastructure resources are not infinite. As applications scale for performance, the availability of on-premise resources becomes an ever-increasing cost issue. How can we run on-prem applications, but also take advantage of the economics of cloud computing (for application processing) when needed?
The concept of just-in-time resource usage has been around for quite a while, and savvy leaders applied the same concept to computing needs even as far back as 2008. Jeff Barr, AWS evangelist coined the term ‘Cloud Bursting’ for an application that resided on-premise but was able to scale up and use cloud-based infrastructure on-demand, especially during peak times. [AWS article on Cloud Burst]
In addition to the cost savings of on-demand commuting resources, cloud-bursting also has some other important benefits:
Flexibility - free up infrastructure resources for critical apps while moving less critical apps to the burst workloads
Capacity management - prevent downtime during peak periods by scaling the workload onto cloud resources
Resiliency - Workload can be moved temporarily to the cloud to mitigate unforeseen hardware failure on-premise. Given these impactful benefits, it is not surprising that cloud-bursting and cloud migration projects are on most corporate agendas today. Just as outlined previously, the decision to temporarily burst processing to cloud must also be evaluated against these requirements.
With that backdrop however, there are many applications that, while residing on premise, may benefit from increased processing afforded on a cloud platform, for a short period or during spikes in demand. There are a number of important considerations in planning for such ‘cloud burst’ projects. Here I outline some of the top considerations that will ensure your success on this journey.
Plan for more than just a single cloud vendor
From orchestration to data management, cloud vendors today provide a multitude of native applications and services that provide an easy way to get up and running.
Speak to any cloud vendor today and you’ll find a myriad of managed solution offerings to ease your cloud journey. Be it relational databases, graph databases, messaging or almost all pieces of a cloud native app stack, cloud vendors offer managed versions of these in a convenient subscription-based offering.
A good example of this is container orchestration. Organizations can choose to manage their containers using open-source upstream Kubernetes, or the many enterprise offerings (RedHat, Rancher, etc) but when deploying on AWS, they have an additional option of using EKS - the AWS managed Kubernetes offering.
These managed offerings are great for applications that reside entirely on a cloud platform but require a measured approach for applications that use bursting. Customizations / configurations that are set up on-prem may be overwritten when using managed services and cause unforeseen impacts on the application.
Even generic functions, such as Kubernetes orchestration can differ significantly between cloud platforms in the way they are set up. Google Kubernetes offering (GKE) can be quite different from Amazon’s equivalent offering (EKS) - both use Kubernetes as the underlying engine, but versions, configurations, etc can make porting between the two prohibitively difficult.
It is important then to ensure cloud-burst workloads are designed for Cloud “Neutrality” and be Cloud Agnostic rather than Cloud specific design.
Avoid Opening up Security Gaps
One of the biggest risk factors that make business leaders apprehensive about moving workload to the cloud is that of security. With full control of on-premise infrastructure, security administrators are much more confident in their ability to batten down their on-prem application environments. It is difficult to have the same level of confidence when one does not have full control of the application infrastructure and networking. This is not to imply that cloud security is any less robust than on premise. In fact, with the lack of legacy applications, and with diligent updates, cloud platforms can sometimes be even more secure than on-prem platforms.
This concern is borne out in the Statista study on cloud adoption, demonstrating that security concerns are one of the top 3 barriers to adoption of cloud by a majority of enterprises.
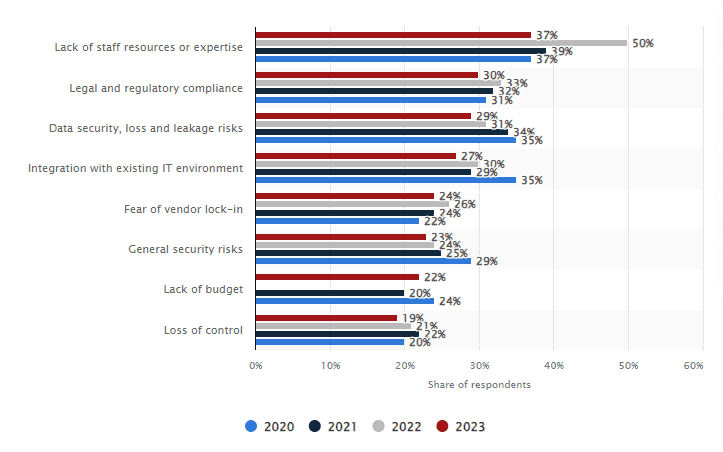
The focus here is that when bursting applications to the cloud, it is very important to ensure a high degree of application (or namespace) isolation. In this context, it is important that a security breach in the cloud does not find its way back to the on-premise environment via a compromised “blast radius”. The term "blast radius" refers to the potential impact and scope of a security incident or breach. Blast radius is a way of measuring the extent to which a security breach or failure can harm an organization, its systems, data, and stakeholders. Minimizing the blast radius of any security breaches has to be planned out in detail before embarking on any cloud burst projects.
Keep reading to understand how Avesha can help address some of these application security concerns for cloud-burst projects.
Overcoming internet Latency issues
It would be counter intuitive to burst a workload to the cloud for performance gains, only to introduce higher latency in the process. Yet this is what many customers do without a plan for mitigation.
As traffic moves from the data center to the cloud, traffic has to traverse multiple network barriers, including egress from on-prem network, route along public internet, ingress into cloud provider network. Each boundary crossing requires address translation and therefore adds latency to the overall traffic. Each border also presents a possible security vulnerability if not addressed properly.
While most enterprises will consider a secure tunnel between their on-prem center and their internet provider, this is still a “wide open” highway for ALL traffic (good and bad). For those that are looking to create a truly secure, Kubernetes application specific connectivity for bursting traffic, Avesha KubeSlice may be the answer. KubeSlice provides a synchronous, secure and isolated connection between on-prem and cloud workloads, but only for a specific namespace - and ideal setup for cloud-bursting - one that is secure and fast.
Global Application / Microservice observability
Another equally important aspect of running cloud-burst workloads is a visibility into the workload itself. The end-to-end microservice performance (on-prem extending into the cloud) needs to be monitored at the namespace level, from a network, infrastructure and service perspective.
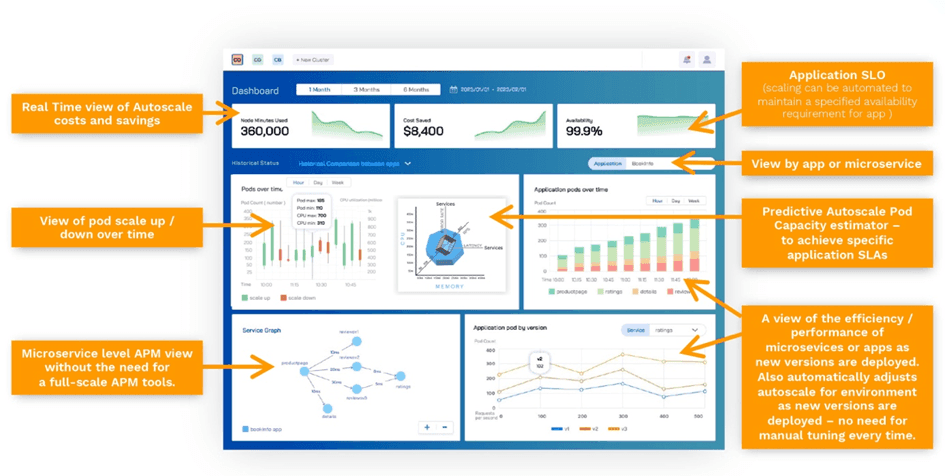
Most tools today, be Application Performance Monitoring (APM)) or Event Based (Datadog, Sysdig), only address application-centric views but do not properly address multi-cluster or hybrid workloads. Nor do they surface specific cluster-cluster views, or pod level performance within a specific namespace that spans on-prem and cloud. Readers should consider tools such as KubeSlice for comprehensive observability of Cloud Burst microservices, and consider augmenting this with tools such as Kentik Kube for overall Kubernetes observability.
Automated Provisioning
To deploy an effective Cloud Burst deployment, enterprises need to incorporate automated processes into the strategy as much as feasible. Recall from the previous graph that lack of skilled resources is a significant hindrance to cloud adoption. The more you can eliminate manual steps in provisioning infrastructure and resources for bursting to the cloud, the more effective it will be.
Not only does it reduce risk from operator fatigue, such as missing key provisioning tasks, it also ensures consistency in the deployment. Using tools such as Terraform and Helm charts and employing Infrastructure as Code (IAC) practices are absolutely essential.
Cloud vendors have recognized this need and released tools to help. Google Cloud Platform for example, has updated and significantly improved Google Autopilot which greatly helps provisioning and automation on GCP.
Autoscaling and Cost control
Equally important as automation is managing the costs of resources utilized during Cloud Bursting.
The basic principle of just-in-time scaling is that you pay for cloud resources only when you use them. This blog article may be helpful for those that want a refresher.
The key consideration here is that computing and application resources are dynamically allocated when needed. The two most common types of autoscaling are reactive and scheduled. As might be expected, reactive autoscaling only kicks in when a certain threshold is reached, such as 90% utilization of the existing nodes, or a certain number of timeouts.
Scheduled autoscaling is just that - autoscaling based on known and expected spikes in application traffic - such as Black Friday, The BIG Game,or a Taylor Swift concert.
Today however, businesses should look beyond these two types and employ predictive, AI based autoscaling and event based autoscaling.
AI Autoscaling, such as the methodology used in Avesha SmartScaler, learns and monitors the actual traffic patterns of an application and predictively scales resources up or down using intelligent algorithms. Using SmartScaler, application owners can finally provide service guarantees and availability commitments for their Kubernetes applications.
An important additional capability of SmartScaler is Event based autoscaling. An event that may be unrelated to the level of utilization of resources, may nevertheless be crucial in managing the burst workload. A good example is the measurements of overall rack temperature. A rack hardware may start to overheat even in situations where the actual utilization of the hardware is low. Under normal autoscaling that only monitors utilization, there may not seem to be any problem in this case. An event based AI autoscaler such as SmartScaler would incorporate temperature readings and nevertheless migrate the workload off the overheating hardware to avoid a possible catastrophic cascading failure.
This great story from The Register (hyperlinked) is a perfect example of such cases:
Overheating datacenter stopped
2.5 million bank transactions
Another emerging idea for autoscaling on cloud computing is the concept of “lights on/lights off” autoscaling.
Under normal circumstances, even when a workload is just running on-prem, there are certain resources or ‘scaffolding’ that needs to be set up and running in the cloud in preparation for cloud-bursting of workloads. This is because most autoscaling tools today can scale workloads only to infrastructure that is already under its remit. The autoscaling target cluster has to be provisioned ahead of time and added into an ‘autoscaling group’. Even keeping the target environment to a minimum does incur cloud costs.
Products such as SmartScaler AI however, are finally able to implement a ‘lights on/lights off’ process - requiring no footprint on the target environment until it is actually needed for the burst workload.
Minimize data egress costs
One final strategy in planning for Cloud Burst workloads is to minimize data egress and the associated costs. Cloud vendors today do not charge for data that is brought onto their platform (ingress) but do charge a hefty fee for data that is transferred out of their platform (egress).
With this in mind, its important to plan cloud-burst workloads where the application may scale out to the cloud, but the data it needs should be retained on-prem as much as possible. In such cases, it is essential to ensure a low latency, secure connection between the source data and the application running on the cloud. KubeSlice point-point synchronous connection is an ideal option - retaining data where it is, but allowing workloads on the cloud to access the data through an east-west connection.
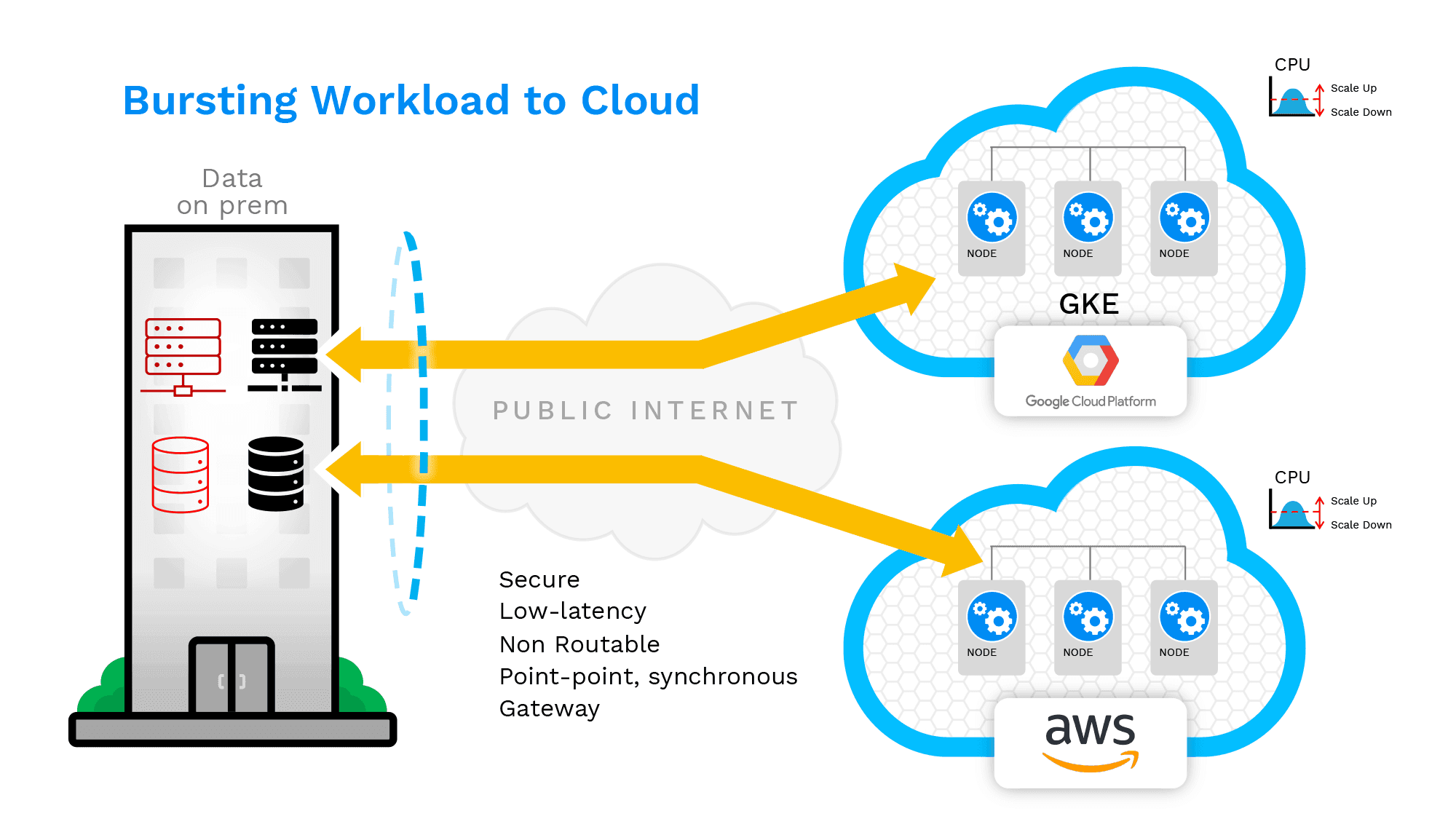
There are a variety of reasons (cloud independence, regulatory requirements , cost management etc) why innovative IT leaders need to enable seamless application bursting between cloud platforms and on-premise deployments . This article outlines some of the key considerations for success.
Contact us for a demo or to explore how we may help accelerate your own journey.




















Copied