KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
Cost Optimization

Uma Tammanagoudar
Technical Writer
Introduction
To deploy complex application microservices at scale in Kubernetes and to control the dynamic expansion and contraction of microservices in response to changes in load, one must use an auto-scaler (such as Horizontal Pod Autoscaling (HPA)).
However, the current autoscalers are reactive, so the resources are overprovisioned to meet Service Level Agreements (SLAs). Overprovisioning gives normal HPA the added headroom to respond to changes in application microservice loading while trying to reduce errors that occur during those changes in load. The DevOps teams responsible for the deployment and upkeep of these apps must adjust the HPA parameters to provide dependable services to end users.
Smart Scaler
Avesha's Smart Scaler is the go-to resource management solution for enterprises looking to optimize their cloud-based operations while keeping costs in check. It offers a proactive and dynamic solution for scaling application microservices. Smart Scaler uses Reinforcement Learning (RL) to precisely anticipate Kubernetes application resource needs after being trained on system and application metrics data from the application cluster. This helps firms meet changing demands while reducing waste and operational expenses.
Smart Scaler, built on predictive analytics and RL, eliminates the need for manual performance tuning of production clusters and avoids overprovisioning resources. This is achieved through digital twin technology that creates a comprehensive set of simulations, using actual production data for accuracy.
Cost Benefits:
- Overprovisioning Cost: Smart Scaler addresses the issue of overprovisioning in Kubernetes clusters, which saves costs. By proactively predicting upcoming load, Smart Scaler enables more effective utilization of available resources thereby reducing the need and cost of the total resources used. Without Smart Scaler, HPA would have otherwise needed to maintain additional resources to provide service during the time it needed to react to changes in load.
- Operational Cost: Manual tuning of HPA parameters by DevOps is not required. Smart Scaler with RL learns the application's requirements and will activate new resources as needed.
Smart Scaler Agent
Smart Scaler’s service runs as a SaaS, but it requires an agent running in the application cluster to collect real-time data and provide scaling recommendations in that cluster. Installing the Smart Scaler Agent on a cluster installs the Inference and Event Agents. Inference and Event agents both scale pods proactively, contributing to cost optimization. To Install the Smart Scaler Agent, see Install Smart Scaler.
Inference Agent
The Inference Agent collects both application and performance metrics. The agent seamlessly integrates with various metrics sources, including Datadog and Prometheus. To maximize application performance, the Inference agent continuously collects real-time metrics from the application microservices you select for Smart Scaling. It will pass only the data you choose to the SaaS where Smart Scaler’s RL functions will inference the optimal number of pods required to achieve your SLA.
To use the RL-based Smart Scaler, you must configure the Inference Agent with the applications and microservices you would like it to manage. The Inference Agent then collects application metrics like errors and latency, as well as the infrastructure performance metrics like RPS, CPU, and memory utilization for each microservice. The metrics data is sent to the SaaS, which predicts the number of pods needed to achieve the desired SLA/SLO (e.g. 1% error rate) for the next sampling interval (e.g. 1 minute).
Event Agent
The Event Agent is configured for autoscaling planned events and includes preconfigured application settings. It dynamically scales the applications based on the pre-defined events. You can add and manage events using the Smart Scaler management console.
Smart Scaler versus Normal HPA
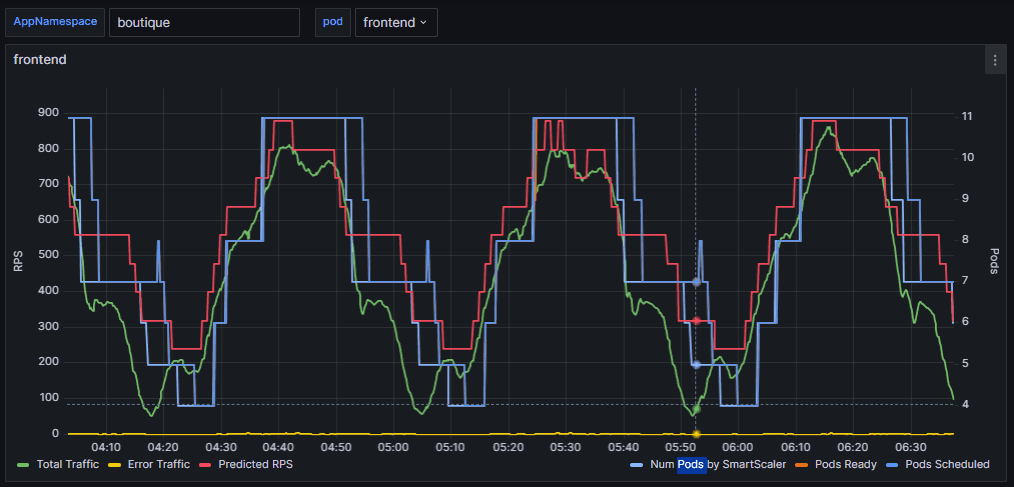
In this example, we will compare Smart Scaler performance with normal HPA. With a higher RPS pattern (frontend max 900), Smart Scaler recommends 11 pods Whereas, the normal HPA recommends 35 pods.
The following graphs show the Smart Scaler recommendation for the incoming traffic ( three hours of traffic). The Num Pods by Smart Scaler indicate that 11 pods are necessary to manage the incoming traffic.
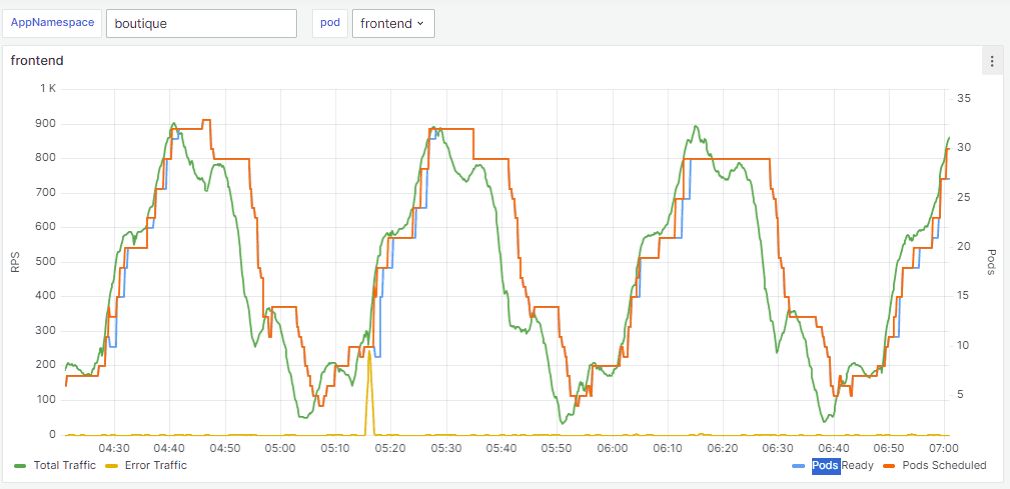
The following graph shows that the normal HPA uses an average of 35 pods to handle the same three hours of traffic and despite that, there is still a spike in errors due to the reactive nature of HPA.
The following graph shows the node count required is 4 using Smart Scaler.
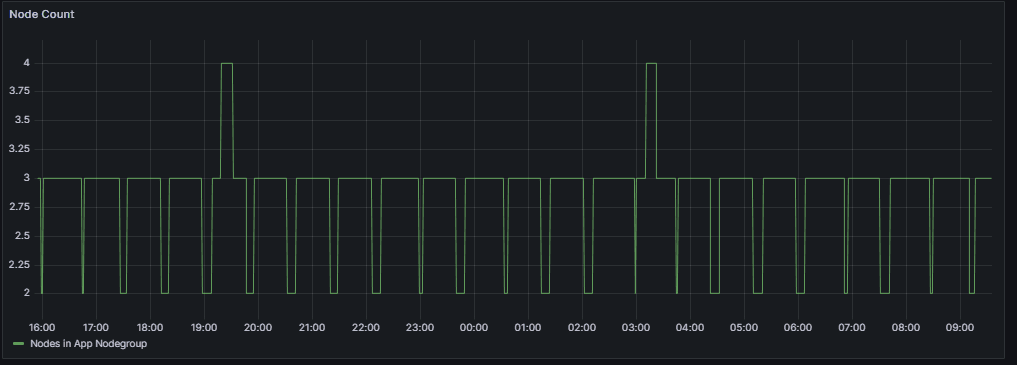
The following graph shows the node count required is 10 using Normal HPA.
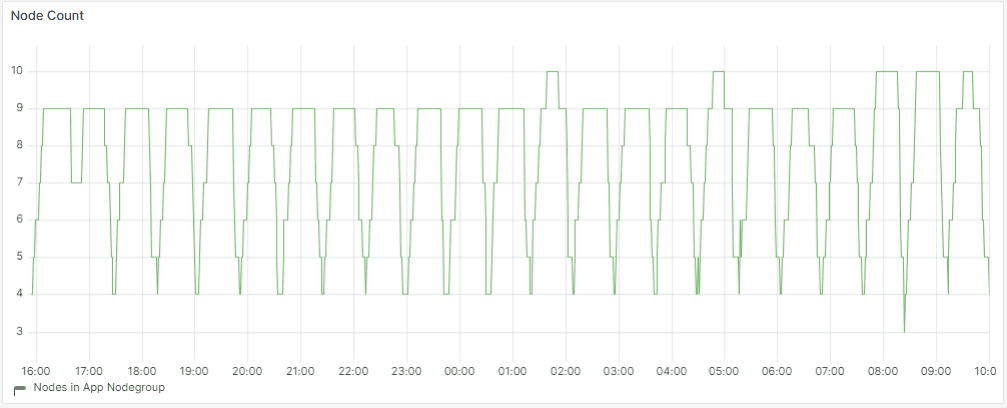
The following figures show that the cluster cost using normal HPA is $19.7 and the cluster cost using Smart Scaler is $7.10 for the same traffic pattern. The total node minutes required by normal HPA is more than the Smart Scaler.
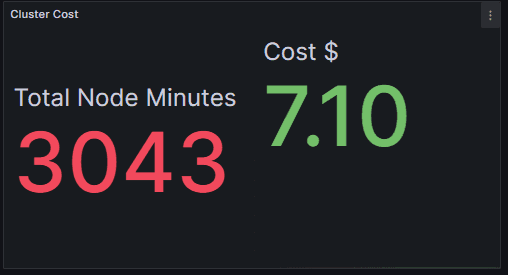
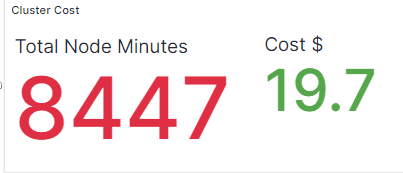
The above example shows how the Smart Scaler helps reduce overprovisioning and operational costs.




















Copied