KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance

KubeBurst
On demand cloud capacity for datacenters

KubeTally
Multi - cluster chargeback by application and teams

KubeAccess
Service gateway for multi-cloud applications
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors

Smart Karpenter
Predictive autonomous scaling of pods and nodes
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
Obliq
Obliq
Obliq adds intelligence and autonomy to Kubernetes


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
Predictive Load Balancing For Cloud Cost Optimization
A Case for Intelligent Load Balancing

Raj Nair
Founder & CEO

Introduction
Modern applications are composed of individual microservices that need to run in one or more locations (cloud regions or edges). On the one hand the loading at each of these microservices can vary with seasonality and other external events that influence the workloads. On the other hand, it is assumed that there is sufficient capacity to handle the load arriving at each of these locations. The platform team can only create static load balancing profiles based on the offerings from various cloud providers resulting in gross overprovisioning — to avoid “getting woken up at night” for an outage. This situation leaves room for considerable cost savings via a ‘predictive’ dynamic load balancer that continuously learns load patterns and creates load balancer profiles dynamically. Likewise, there are several opportunities for improvement including the use of intelligent traffic steering based on location of the service requests and available capacity at the service locations. In this brief, we examine the rationale for such a design.
Intelligent Traffic Steering
A client request for service gets “routed” by DNS in a weighted round-robin fashion, where the request is resolved to the IP addresses of service locations in proportion to the weights of the individual locations. These weights are typically fixed in advance and do not change automatically. An obvious improvement would be to utilize a more dynamic system, where the weights are changed dynamically based on traffic patterns. For example, a localized weekend or seasonal pattern for Christmas or other holidays can be utilized to control the weights and subsequent direction of traffic toward those locations that are best suited to handle the load.
Of course, the challenge lies in the algorithm used to derive the weights and to do so in time. This is where the use of AI/ML can be effective with a traffic pattern predictor (Regression Model) together with an RL (Reinforcement Learning) model to continuously take the right actions and adapt to varying load patterns resulting in proactive traffic direction to the most optimal locations measured by the overall application metrics such as failure rates or latency.
A direct benefit of this approach is avoid having to over-provision all locations to handle the highest loading and capital costs because n locations would require n * M capacity, where M is the capacity to handle the maximum load. In contrast, an efficient provisioning will only require the sum, S, of the operating capacity,ci, at n locations, i.e.,
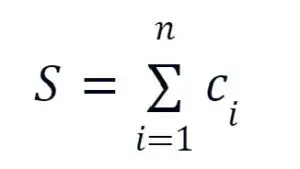
with some allowance for over provisioning, i.e., S=kM, where k
The efficiency of the system can be measured as
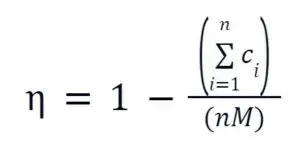
The better the prediction, the closer this efficiency will get to 1. An efficiency of 0 is the most inefficient provisioning of maximum resources (M) at all locations.
Next, we will examine another opportunity for improvement, viz, the auto-scaling of pods at a location.
Application-aware Predictive Auto-scaling
Traffic from the Internet arrives at one or more ingress points front-ended by an API gateway, firewall and load balancer and gets distributed to the microservices based on the application logic. At each of these microservices, the horizontal pod auto-scaler provided by the cloud providers elastically increase or decrease pods based on simple threshold-crossing schemes based on CPU utilization or other infrastructure metrics.
Current approaches to pod auto-scaling do not have any predictive or dynamic capabilities. A platform team engineer typically sets a low threshold for CPU utilization at which to trigger cluster auto-scaling – typically provided by the cloud provider. This results in great inefficiencies because most of the nodes are under-utilized most of the time waiting for that spike to occur.
Just like in the case of traffic steering, an improvement would be to use a traffic pattern predictor in combination with an RL model to scale pods up or down and in turn achieve the desired application performance and cost quantified by application metrics such as percentage of failed requests and number of pods or nodes. In other words, the number of pods can be scaled up or down in a proactive manner based on traffic patterns rather than reactively based on loading or losses avoiding the over-provisioning and wastage that are typical of current practices.
In a recent study, Avesha found almost 70% cost savings (see Table below) for some microservices in a hyper-scalar cloud provider’s auto-scalar versus using a predictive auto scaling approach. This is shown in the charts below. Note how the hyper-scalar’s auto-scaler (chart on the left) falls behind when load (blue line) increases causing SLA violations (red line). The orange line shows the number of pods in use. Note also how the predictive auto-scalar from Avesha (shown on the left) can keep up the with varying loading patterns with just-in-time pod scaling up and down. This is reflected in the almost perfect SLA performance.
Table 1: RL Autoscaling Results on Boutique App
| Service Name | RL HPA: Pods Used | Reg HPA: Pods Used | % Savings | Max RPS |
|---|---|---|---|---|
| cart | 1321 | 1787 | 26 | 400 |
| currency | 1940 | 4683 | 59 | 1000 |
| frontend | 1995 | 5773 | 65 | 350 |
| productcatalog | 1639 | 5824 | 72 | 1700 |
| recommendation | 1548 | 2706 | 43 | 250 |
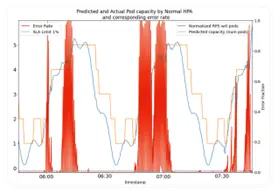
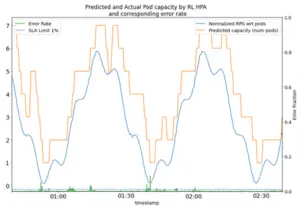
Conclusion
In this paper we have demonstrated a strong case for using AI/ML (particularly RL) in optimizing cloud resource usage. There are benefits from both a reduction in down time by proactively steering traffic to more available sites as well as a significant reducing in spend (up to 70%) through predictive autoscaling that provides the added benefit of helping use lesser energy and a smaller carbon footprint to help save the planet!
This article was also featured by the same author on the ONUG blog page here.




















Copied