KubeSlice


Avesha Enterprise for KubeSlice
Service Connectivity Layer for managing fleet of clusters for better application performance
Smart Scaler
Smart Scaler
Predictive autoscaling based on application behaviors
Elastic Grid Service


EGS
Single/Multi-cluster and multi-cloud GPU provisioning and management platform
1.16
KubeSlice Enterprise
released version 1.16.0
2.17
Smart Scaler
released version 2.17.0
1.16
Elastic Grid Service
released version 1.16.0


EGS Resources
Explore Resources for Elastic Grid Service

Analyst Reports
Navigating Key Metrics for Growth and Success

Blog
Source for Trends, Tips, and Timely Topics

Documentation
The Blueprint for Mastering Tools and Processes

Customer Case Studies
Success stories from our valued customers and partners










Avesha Resources / Blogs
Kafka Multi-Cluster Deployment on Kubernetes - simplified !

Ray Edwards
VP - Northeast Sales, Avesha

What is Kafka
Commonly known simply as Kafka, Apache Kafka is an open-source event streaming platform maintained by the Apache Software Foundation. Initially conceived at LinkedIn, Apache Kafka was collaboratively created by Jay Kreps, Neha Narkhede and Jun Rao, and subsequently released as an open-source project in 2011. Wiki Page
Today, Kafka is one of the most popular event streaming platforms designed to handle real-time data feeds. It is widely used to build scalable, fault-tolerant, and high-performance streaming data pipelines.
Kafka's uses are continually expanding, with the top 5 cases nicely illustrated by Brij Pandey in the accompanying image.
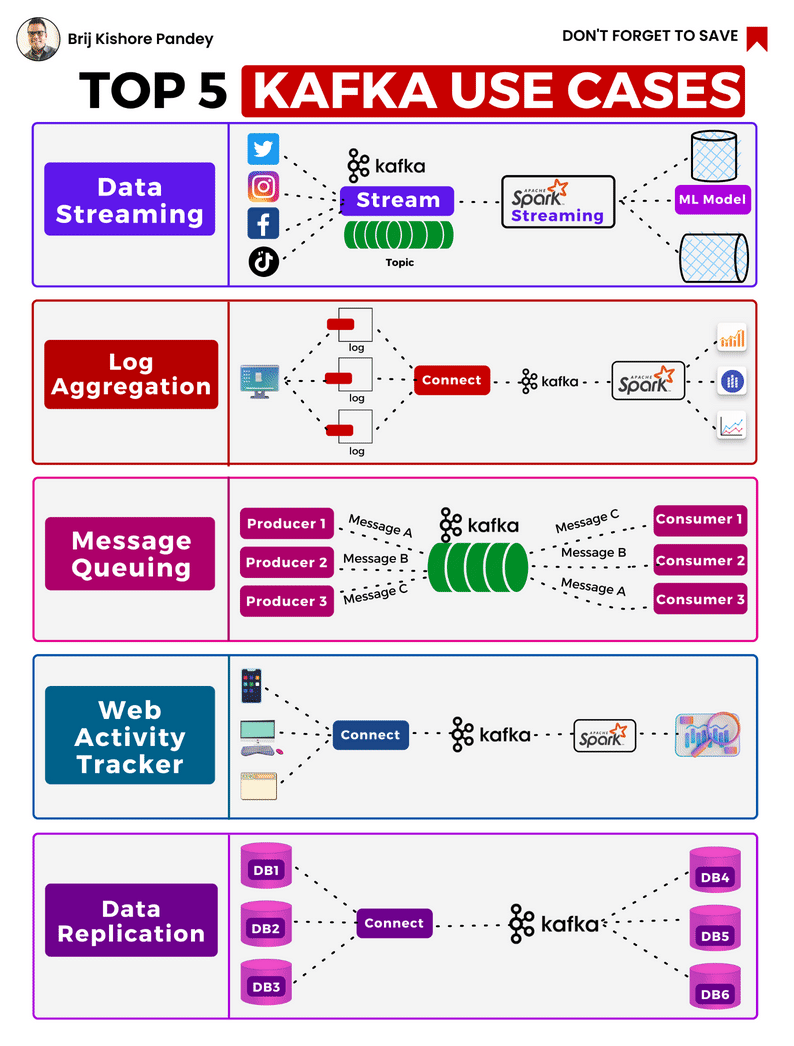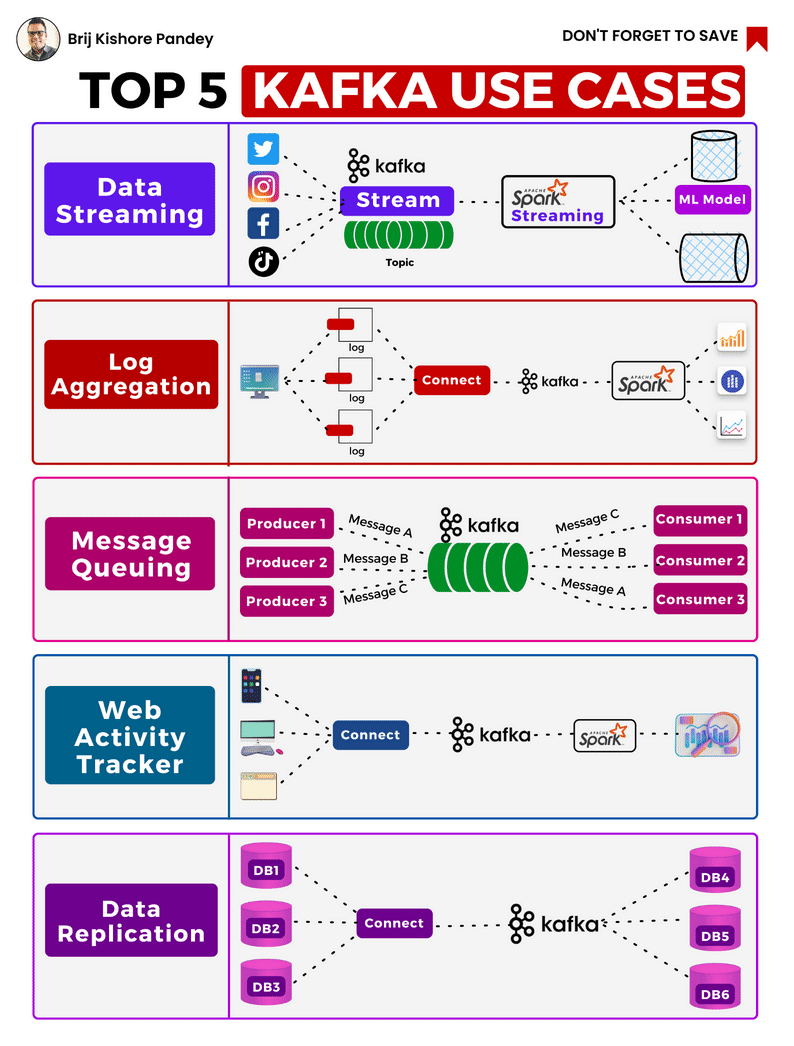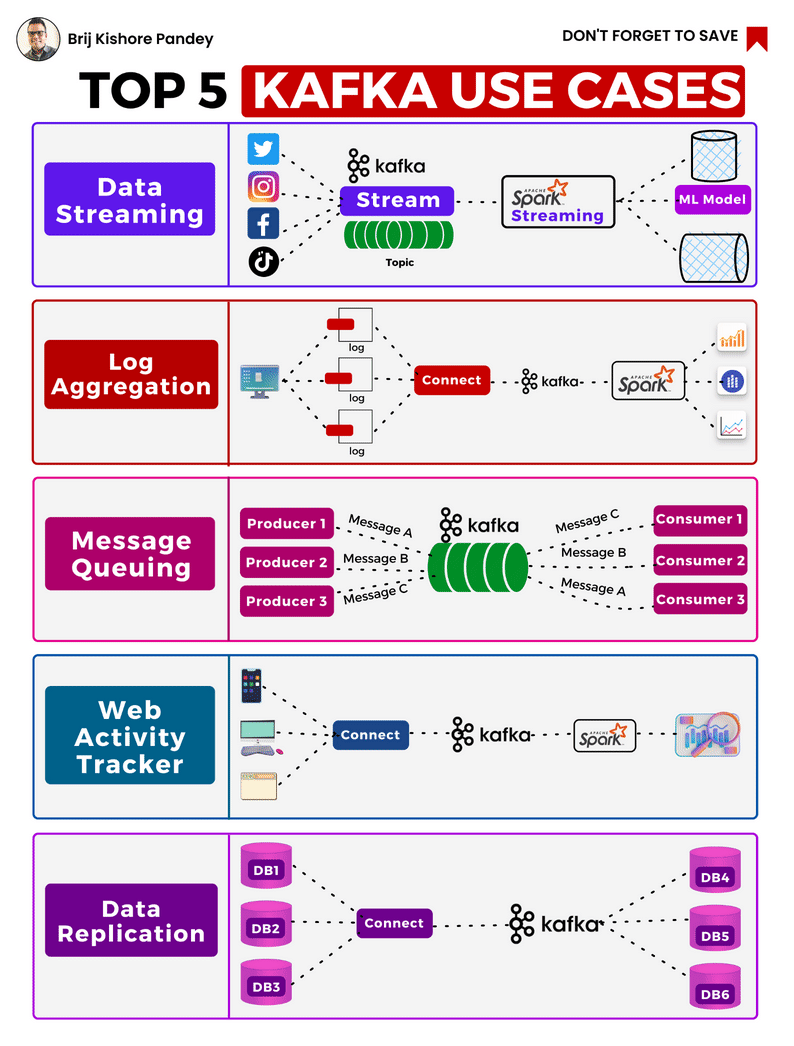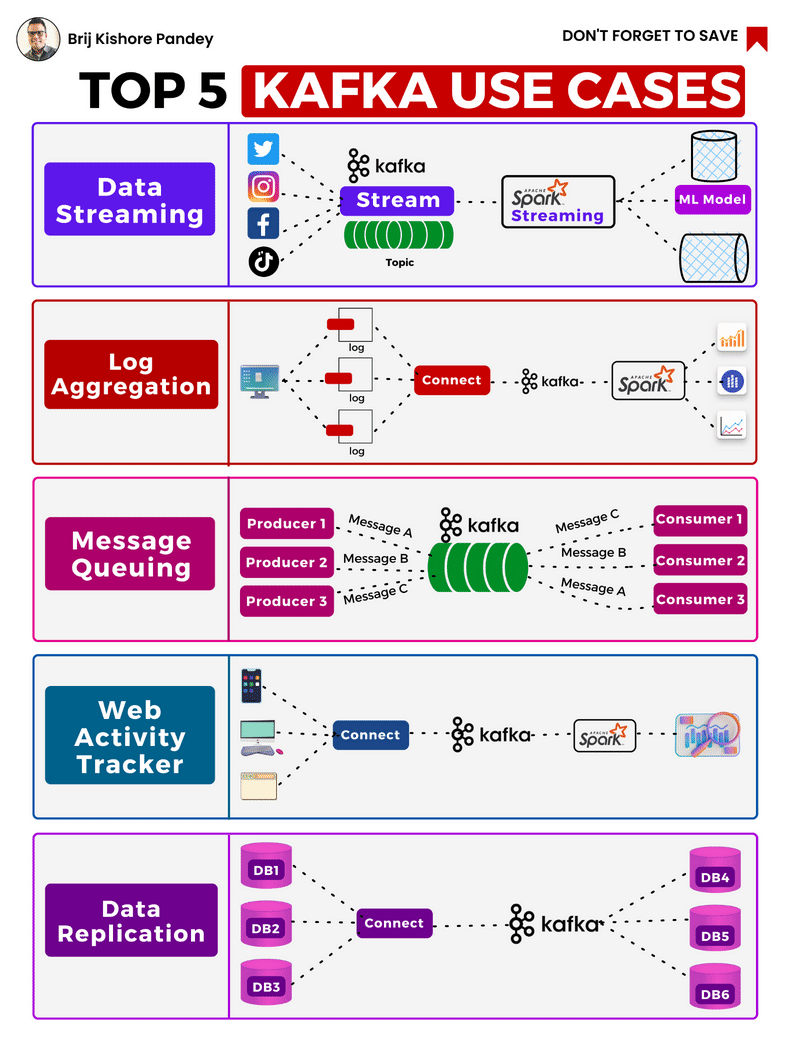
As a brief primer, it is important to understand the components of the Kafka platform and how they work..
Kafka works as a distributed event streaming platform, designed to handle real-time data feeds efficiently. It operates based on the publish-subscribe messaging model and follows a distributed and fault-tolerant architecture. It maintains a persistent, ordered, and partitioned sequence of records called "topics." Producers write data to these topics, and consumers read from them. This enables decoupling between data producers and consumers and allows multiple applications to consume the same data stream independently.
Key components of Kafka include:
1. Topics and Partitions: Kafka organizes data into topics. Each topic is a stream of records, and the data within a topic is split into multiple partitions. Each partition is an ordered, immutable sequence of records. Partitions enable horizontal scalability and parallelism by allowing data to be distributed across multiple Kafka brokers.A Kafka server, with unique ID that forms the basic component of a Kafka cluster and is responsible for managing messages between producers and consumers)
2. Producers: Producers are applications that write data to Kafka topics. They publish records to specific topics, which are then stored in the topic's partitions. Producers can send records to a particular partition explicitly or allow Kafka to determine the partition using a partitioning strategy.
3. Consumers: Consumers are applications that read data from Kafka topics. They subscribe to one or more topics and consume records from the partitions they are assigned to. Consumer groups are used to scale consumption, and each partition within a topic can be consumed by only one consumer within a group. This allows multiple consumers to work in parallel to process the data from different partitions of the same topic.
4. Brokers: Kafka runs as a cluster of servers, and each server is called a broker. Brokers are responsible for handling read and write requests from producers and consumers, as well as managing the topic partitions. A Kafka cluster can have multiple brokers to distribute the load and ensure fault tolerance.
5. Partitions/Replication: To achieve fault tolerance and data durability, Kafka allows configuring replication for topic partitions. Each partition can have multiple replicas, with one replica designated as the leader and the others as followers. The leader replica handles all read and write requests for that partition, while followers replicate the data from the leader to stay in sync. If a broker with a leader replica fails, one of the followers automatically becomes the new leader to ensure continuous operation.
6. Offset Management: Kafka maintains the concept of offsets for each partition. An offset represents a unique identifier for a record within a partition. Consumers keep track of their current offset, allowing them to resume consumption from where they left off in case of failure or reprocessing.
7. ZooKeeper : While not part of Kafka itself, ZooKeeper is often used to manage the metadata and coordinate the brokers in a Kafka cluster. It helps with leader election, topic and partition information, and managing consumer group coordination. [Note: Zookeeper metadata management tool, will soon be phased out in favor of Kafka Raft, or KRaft, a protocol for internally managed metadata]
Overall, Kafka's design and architecture make it a highly scalable, fault-tolerant, and efficient platform for handling large volumes of real-time data streams. It has become a central component in many data-driven applications and data infrastructure, facilitating data integration, event processing, and stream analytics
A typical Kafka architecture would then be as follows :
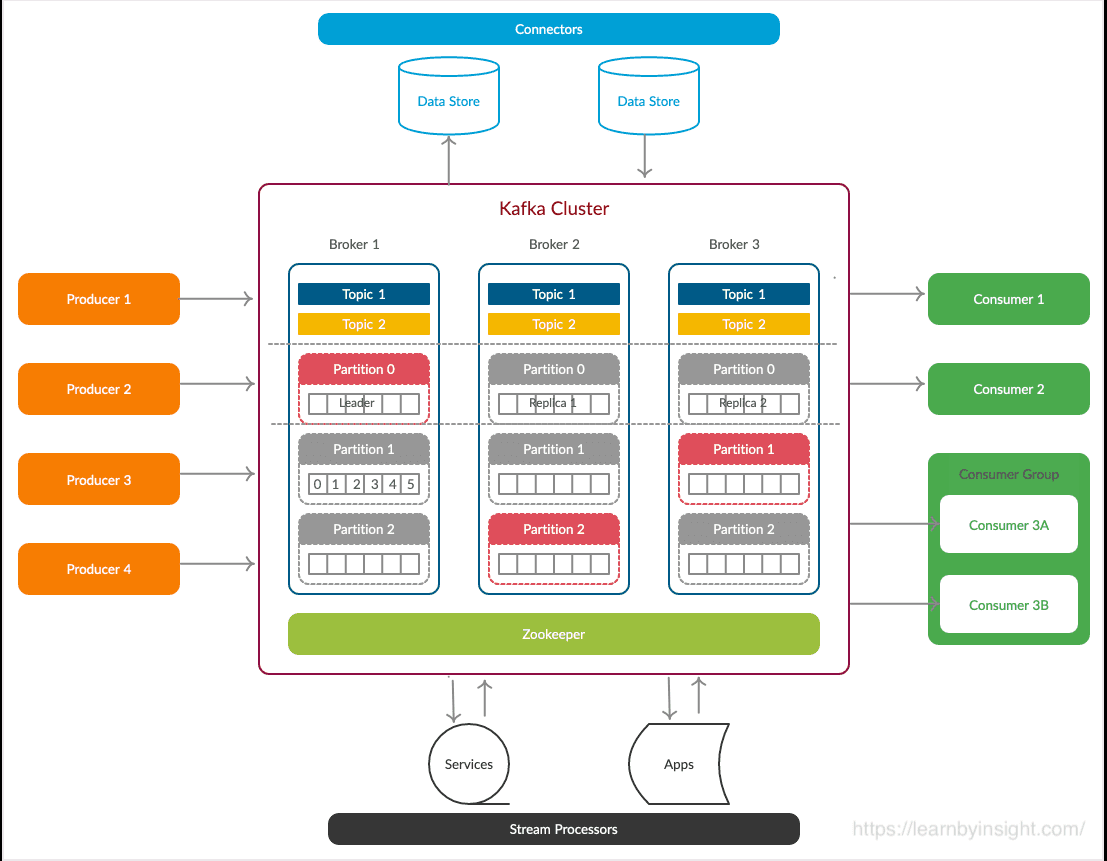
Kafka clustering refers to the practice of running multiple Kafka brokers together as a group to form a Kafka cluster. Clustering is a fundamental aspect of Kafka's architecture, providing several benefits, including scalability, fault tolerance, and high availability. A Kafka cluster is used to handle large-scale data streams and ensure that the system remains operational even in the face of failures.
In the cluster, Kafka topics are divided into multiple partitions to achieve scalability and parallelism. Each partition is a linearly ordered, immutable sequence of records. Partitions therefore allow data to be distributed across multiple brokers in the cluster.
It should be noted that a minimum Kafka cluster consists of 3 Kafka brokers, each of which can be run on a separate server (virtual or physical). The 3 node guidance is to help avoid a split brain scenario in case of a broker failure. (Nice article by Dhinesh Sunder Ganapathi that goes into more detail.)
Kafka and Kubernetes
As more companies adopt Kafka, there is also an increasing interest in deploying Kafka on Kubernetes.
In fact, the most recent Kubernetes in the Wild report 2023 by Dynatrace shows that over 40% of large organizations run their open source messaging platform within Kubernetes - the majority of this being Kafka.
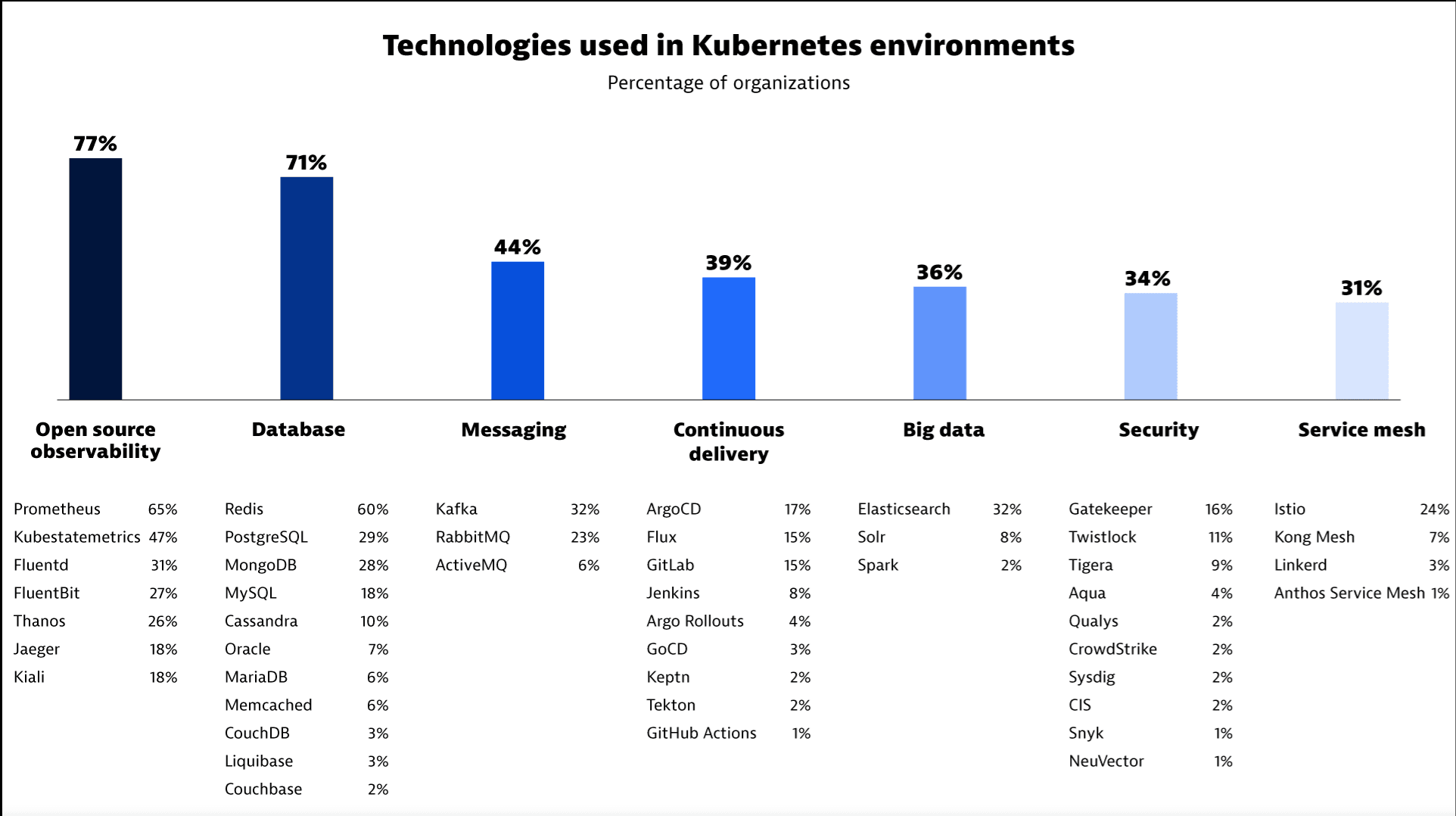
https://www.dynatrace.com/news/blog/kubernetes-in-the-wild-2023/#&gid=0&pid=1
The same report also makes a bold claim , that “Kubernetes is emerging as the ‘operating system’ of the cloud.”
It is imperative then, for Kafka administrators to understand the interplay between Kafka and Kubernetes, and how to implement these appropriately for scale.
The Case for Multi Cluster Kafka
Running a Kafka cluster in a single Kubernetes cluster setup is fairly straightforward and enables scalability as needed in theory. In production however, the picture can get a bit murky.
We should distinguish the use of the term cluster between Kafka and Kubernetes. A Kubernetes deployment also uses the term cluster to designate a grouping of connected nodes, referred to as Kubernetes cluster. When the Kafka workload is deployed on Kubernetes, you will end up with a Kafka cluster running inside a Kubernetes cluster, but more relevant to our discussion, you may also have a Kafka cluster that spans multiple Kubernetes clusters - for resiliency, performance, data sovereignty etc (ie Multi-region Kafka clusters).
To begin with, a Kafka workloads itself is not designed for multi-tenant Kubernetes setups. In technical terms, Kafka does not understand concepts such as Kubernetes namespaces or resource isolation. Within a particular topic, there is no easy mechanism to enforce security access restrictions between multiple user groups.
Additionally, different Kafka workloads may have different update frequency and scale requirements eg batch application vs. real-time application. Combining two such Kafka workloads into a single Kubernetes cluster could cause adverse impacts or consume much more resources than necessary.
Data sovereignty and regulatory compliance can also impose restrictions on co locating data and topics in a specific region or application.
Resiliency of course is another strong driving force behind the need for a Kafka cluster to be deployed across multiple Kubernetes clusters . While Kafka clusters are designed for fault tolerance of topics, we still have to plan for a catastrophic failure of an entire Kubernetes cluster. In such cases, the need for a fully replicated Kafka cluster enables proper business continuity planning.
For businesses that are migrating workload to the cloud or have a hybrid cloud strategy, you may want to set up multiple Kafka clusters and perform a planned workload migration over time rather than a risky full scale Kafka migration.
These are just a few of the reasons why in practice, enterprises find themselves having to create Multi-region Kafka clusters, across multiple Kubernetes clusters, that nevertheless need to interact with each other.
Multi Cluster Kafka
In order to have multiple Kafka clusters that are connected to each other, key items from one cluster must be replicated to the other cluster(s). These include the topics, offsets and metadata. In Kafka terms, this duplication is considered Mirroring.
There are two approaches of multi-cluster setups that are possible. Stretched Clusters or Connected Clusters.
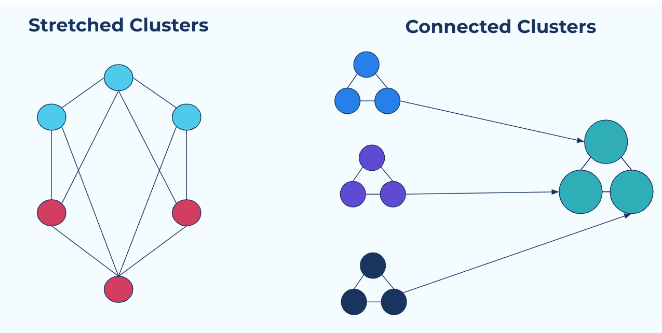
Stretched clusters - Synchronous replication
A stretched cluster is a logical cluster that is ‘stretched’ across several physical clusters. Topics and replicas are distributed across the physical clusters, but since they are represented as a logical cluster, the applications themselves are not aware of this multiplicity.
Stretched clusters have strong consistency and are easier to manage and administer. Since applications are unaware of the existence of multiple clusters, they are easier to deploy on stretched clusters, compared to connected clusters.
The downsides of stretched clusters are that it requires a synchronous connection between the clusters. They are not ideal for a hybrid cloud deployment, and will require a quorum of at least 3 clusters to avoid a ‘split-brain’ scenario.
Connected Clusters - Asynchronous replication
A Connected Cluster on the other hand, is deployed by connecting multiple independent clusters. These independent clusters could be running in different regions or cloud platforms and are managed individually.
The primary benefit of the connected cluster model is that there is no downtime in cases of a cluster failure, since the other clusters are running independently. Each cluster can also be optimized for its particular resources.
The major downside of connected clusters is that it relies on asynchronous connection between the clusters. Topics that are replicated between the clusters are not ‘copy on write’ but rather , depend on eventual consistency. This can lead to possible data loss during the async mirroring process.
Additionally, applications that work across connected clusters have to be modified to be aware of the multiple clusters.
Before we address the solution to this conundrum, I’ll briefly cover the common tools on the market to enable Kafka cluster connectivity.
Open Source Kafka itself ships with a mirroring tool called Mirror Maker.
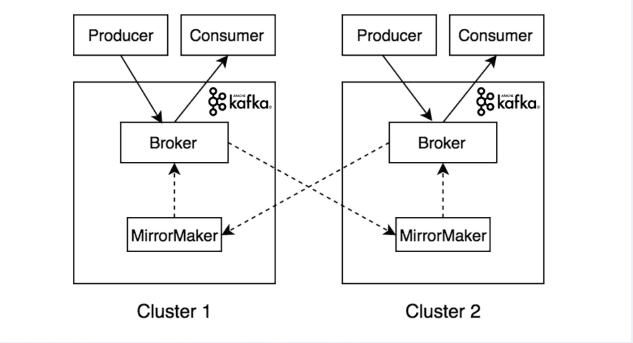
Source: https://www.altoros.com/blog/multi-cluster-deployment-options-for-apache-kafka-pros-and-cons/
Mirror Maker duplicates topics between different clusters via a built in producer. This way data is cross replicated between clusters with eventual consistency, but without interrupting individual processes.
It is important to note that while Mirror Maker is simple in its concept, setting up Mirror Maker at scale can be quite a challenge for IT organizations. Managing IP addresses, naming conventions, number of replicas etc must be done correctly or it could lead to what is known as ‘infinite replication’ where a topic is infinitely replicated, leading to eventual crash.
Other downsides of Mirror Maker is the lack of dynamic configuration of allowed/disallowed lists for updates. Mirror Maker also does not sync topic properties properly, which makes it an operational headache at scale when adding or removing topics to be replicated. Mirror Maker 2 attempts to fix some of these challenges but many IT shops still struggle to get Mirror Maker set up correctly.
Other Open Source tools for Kafka replication include Mirus from Salesforce, uReplicator from Uber and customised Flink from Netflix.
For commercial licensed options, Confluent offers two options, Confluent Replicator and Cluster Linking. Confluent Replicator is essentially a Kafka Connect connector that provides a high-performance and resilient way to copy topic data between clusters. Cluster Linking is another offering, developed internally and is targeted at multi region replication while preserving topic offsets.
Even so, Cluster Linking is an asynchronous replication tool with data having to cross network boundaries and traverse public traffic pathways.
As should be clear by now, Kafka replication is a crucial strategy for production applications at scale, the question is which option to choose.
Imaginative Kafka administrators will quickly realize that you may need connected clusters and stretched clusters, or a combination of these deployments, depending on the application performance and resiliency requirements.
What is daunting however, is the exponential challenges of setting up the cluster configurations and managing these at scale across multiple clusters. Is there a more elegant way to solve this nightmare?
The answer is Yes!
KubeSlice by Avesha is an exquisitely simple way to get the best of both worlds. By creating a direct Service Connectivity between clusters or namespaces, KubeSlice obviates the need for manually configuring individual connectivity between Kubernetes clusters running Kafka instances.
At its core, KubeSlice creates a secure, synchronous Layer 3 network gateway between clusters; isolated at the application or namespace level. Once this is set up, Kafka administrators are free to deploy Kafka brokers in any of the Kubernetes clusters.
With this setup, each broker has a synchronous connectivity to every other broker that is joined via the slice, even though the brokers themselves may be on separate clusters. This effectively creates a stretched cluster between the brokers and provides the benefit of a strong consistency, and low administration overhead.
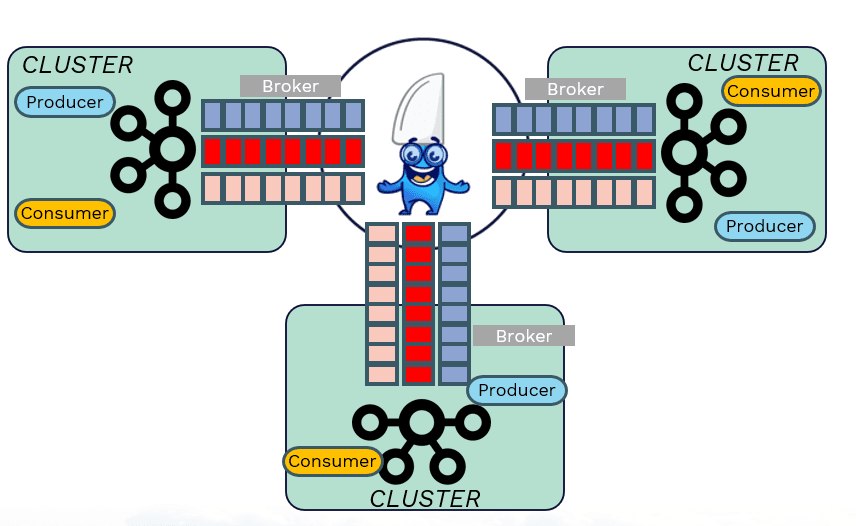
Have your cake and eat it too !
For those that may want to deploy Mirror Maker into their clusters, this can be done with minimal effort since the connectivity between the clusters is delegated to KubeSlice. Thus, Kafka applications can have the benefits of synchronous (speed, resiliency) AND asynchronous (independence, scale) replication in the same deployment with the ability to mix and match the capabilities as needed. This is true of on-prem data centers, across public clouds or any combinations of these in a hybrid setup.
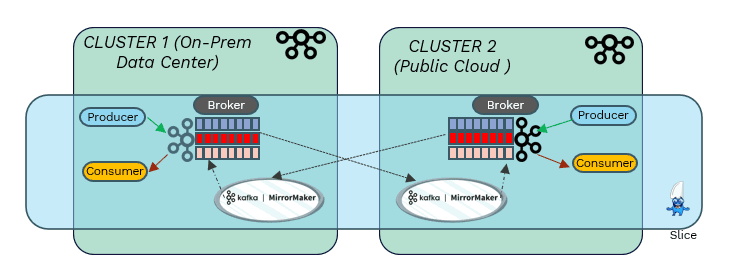
The best part is that KubeSlice is a non-disruptive deployment, meaning that there is no need to uninstall any tool already deployed. It is simply a matter of establishing a slice and adding the Kafka deployment onto that slice.
This blog provided a brief overview of Apache Kafka and has touched on some of the more common use cases. We covered the current tools available to scale Kafka deployments across multiple clusters and discussed the advantages / disadvantages of each. Finally, the article also introduced Kubeslice - the emerging service connectivity solution that simplifies Kafka multi-cluster deployments and removes the headaches associated with configuring Kafka replication across multiple clusters at scale.
A couple of links that readers may find useful:
An older blog of best practices running Kafka on AWS(before KubeSlice was introduced)
What Every Engineer should know about distributed log - by Jay Kreps (essential reading !)




















Copied